目录
什么是Thrift?
Thrift 是一套轻量级、跨语言、全栈式的RPC(远程过程调用)解决方案,最初由Facebook开发,后面进入Apache开源项目,包含了代码生成、序列化框架和RPC框架三大部分。大致相当于protoc + protobuffer + grpc。三部分的具体作用如下:
- 代码生成:Thrift提供了一个IDL(接口描述语言),用于定义数据类型和服务接口。通过Thrift编译器,可以根据IDL文件生成不同编程语言的代码。这些代码包括数据结构、客户端和服务器端的接口,使得不同语言的系统可以无缝地进行通信。
- 序列化框架:Thrift提供了高效的序列化和反序列化机制,用于将数据对象转换为字节流进行传输。Thrift支持多种传输协议(如二进制、压缩、JSON等)和传输层(如TCP、HTTP等),以满足不同的性能和兼容性需求。
- RPC框架:Thrift包含了一个强大的RPC框架,用于实现远程过程调用。通过Thrift生成的代码,客户端可以像调用本地函数一样调用远程服务,而服务器端则可以方便地实现这些服务接口。Thrift的RPC框架支持多种传输协议和传输层,确保了跨语言和跨平台的通信一致性。
整体架构图:
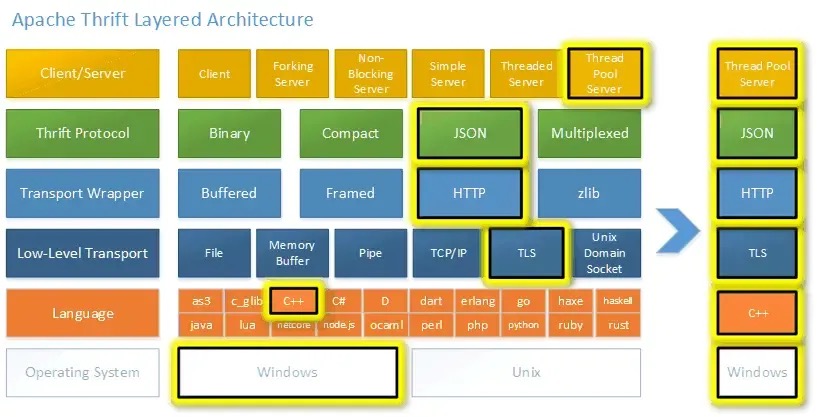
Thrift架构
总体
Thrift技术栈分层从下向上分别为:传输层(Transport Layer)、协议层(Protocol Layer)、处理(Processor Layer)和服务层(Server Layer)。
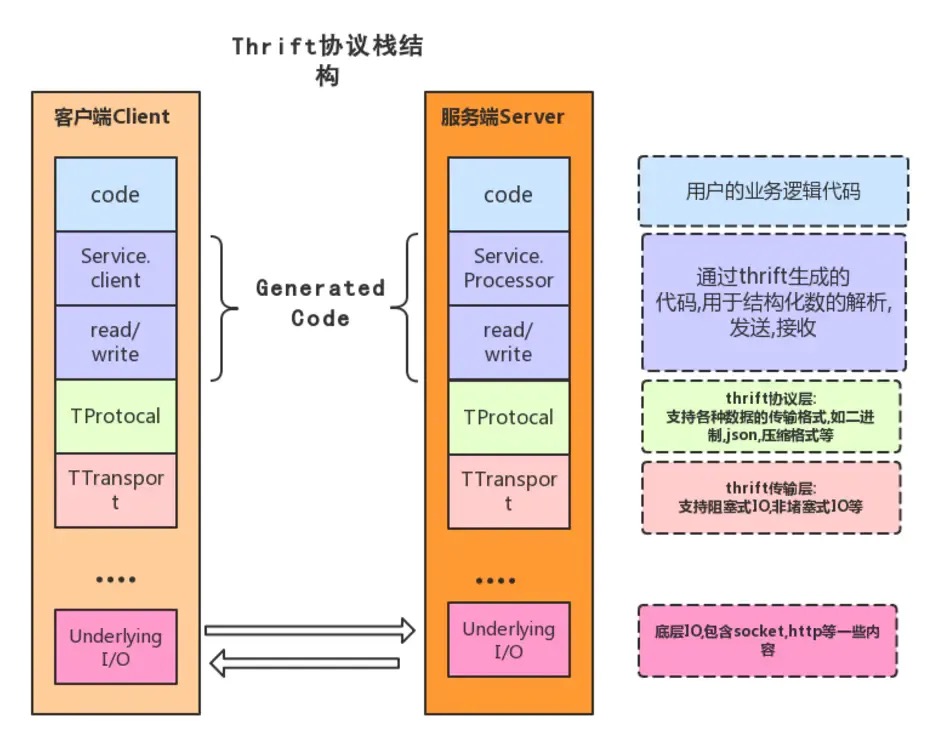
- 传输层(Transport Layer):传输层负责直接从网络中读取和写入数据,处理底层的数据传输细节,如连接管理、数据读写等;它定义了具体的网络传输协议,比如TCP/IP传输等。
- 协议层(Protocol Layer):协议层定义了数据传输格式,负责网络传输数据的序列化和反序列化,比如说JSON、XML、二进制数据等。
- 处理层(Processor Layer):处理层定义了服务端处理请求的逻辑,包括接收请求、调用处理函数、返回响应等,它是由具体的IDL(接口描述语言)生成的,封装了具体的底层网络传输和序列化方式,它从Protocol中读取方法名和参数,调用用户编写的对应方法,将结果写到protocol中。
- 服务层(Server Layer):提供服务端的基础设施,如监听端口、接收连接、调用处理器等。
- IO层(Underlying I/O):底层IO负责实际的数据传输,包括socket、文件和压缩数据流等。
数据类型
| 数据类型 | 类型标志(一个字节) | 值 |
|---|---|---|
| bool | 2 | 一个字节 |
| byte | 3 | 一个字节 |
| double | 4 | 八个字节 |
| i16 | 6 | 两个字节值 |
| i32 | 8 | 四个字节值 |
| i64 | 10 | 八个字节值 |
| string | 11 | 四个字节数据长度+数据的值 |
| binary | 11 | 四个字节数据长度+数据的值 |
| struct | 12 | 多个连续的field数据+一个字节停止符(0) |
| map | 13 | 一个字节的key类型标志+一个字节的val类型标志+四个字节的数据长度+数据的值(key+val) |
| set | 14 | 一个字节的val类型标志+四个字节的数据长度+数据的值 |
| list | 15 | 一个字节的val类型标志+四个字节的数据长度+数据的值 |
传输层/Transport
传输层为网络IO操作提供了一个简单抽象,使得Thrift的其它部分(序列化、请求处理等)与底层网络处理解耦。传输层主要有两个接口:TTransport和TServerTransport。
- TTransport代表的是一个连接,主要方法有:open()、close()、read()、write()、flush()。TTransport接口的主要实现有:
- TSocket:对应的就是TCP连接Socket对象,负责管理具体的connection,remote addr,timeout。此外还有一个TSSLSocket,就是使用了SSL加密的TSocket。
- TBufferedTransport:TSocket是不带buffer的,每次读写都直接与操作系统内核交互,效率不高。因此有了带buffer的TBufferedTransport。TBufferedTransport内部包含了一个bufio.ReadWriter的缓冲对象,每次调用write方法会向buffer中写入,当buffer满了或者调用了flush方法,才会一次性将buffer中的内容发送到socket中。
- TFramedTransport:TFramedTransport也是带有buffer的,与TBufferedTransport不同的是,TFramedTransport是按帧发送内容的。当需要将buffer中的内容发送到socket中时(调用了flush方法),会先将buffer中的字节长度(4个byte)发送到socket中,然后才是字节内容。长度+内容的组合被称为帧(frame),一帧的最大长度为16M。framed和unframed传输是不兼容的。TFramedTransport主要是针对异步请求场景的,需要获取到完整的请求数据才会开始处理请求。在一次请求数据量比较大的时候,内存占用会很高。
- TServerTransport主要用户服务端接受客户端请求并为连接对象创建一个TTransport。主要方法有open()、listen()、accept()、close()。主要实现为TServerSocket。
协议层/Protocol
协议层定义了一种将内存中的数据结构映射到传输格式的机制,它指定了各种数据类型在使用底层传输时如何编码/解码。协议实现管理编码方案并负责(反)序列化,因此也可以称为序列化协议。协议的一些例子包括 JSON、XML、纯文本、压缩二进制等。
序列化是将数据结构或对象转换成可以存储和传输的字节序列的过程。
协议层定义了一个TProtocol接口。TProtocol中定义了一系列WriteXxx()和ReadXxx()方法,提供的就是对数据的编码和解码。Thrift通过不同的Protocol实现类来提供不同序列化方式。在序列化协议上总体划分为文本(text)和二进制(binary)协议。常用协议有以下几种:
- TBinaryProtocol:二进制编码格式进行数据传输
- TCompactProtocol:高效率的、密集的二进制编码格式进行数据传输
- TJSONProtocol: 使用JSON文本的数据编码协议进行数据传输
- TSimpleJSONProtocol:只提供JSON只写的协议,适用于通过脚本语言解析
前面讲序列化的时候,特别指出是序列化协议,但Thrift实现的时候没有区分那么明显,我们一般说的BinaryProtocol和CompactProtocol实现其实就是通讯协议(可以理解里面包含了序列化协议),就是在前面在序列化协议基础上添加了Message传输的协议部分。之所以分开讲,是更了方便理解Thrift不仅仅是RPC框架还是个序列化框架。回到通讯协议,典型常见的HTTP协议为例,可以理解主要含三部分:路由信息(URL)+控制信息(Header)+数据负载(Body),Thrift通讯协议也是如此,下面主要分析一下BinaryProtocol通讯协议的实现。
首先BinaryProtocol分为严格模式和非严格模式,严格模式下会带上版本Version信息,非严格模式没有版本,默认为严格模式。其中通讯的消息类型主要有四种typeId:
- CALL:值为1, 请求;
- REPLY:值为2,响应;
- EXCEPTION:值为3,异常;
- ONEWAY:值为4,无返回值请求。
整个通讯协议具体实现如下:
- 严格模式
四个字节的版本(含调用类型),四个字节的消息名称长度,消息名称,四个字节的流水号,消息负载数据的值,一个字节的结束标记。伪代码如下:
goversion := uint32(VERSION_1) | uint32(typeId)
WriteI32(int32(version))
WriteString(name)
WriteI32(seqId)
WriteBody(body)
WriteByte(STOP)
- 非严格模式
四个字节的消息名称长度,消息名称,一个字节调用类型,四个字节的流水号,消息负载数据的值,一个字节的结束标记。
goWriteString(name) WriteByte(typeId) WriteI32(seqId) WriteBody(body) WriteByte(STOP)
处理层/Processor
处理层主要负责读取解码后的数据和输出编码前的数据,处理的是具体的消息交换。
消息交换过程
- 客户端发送消息(类型Call或Oneway),TMessage 包含一些元数据和要调用的方法的名称。
- 客户端发送方法参数(由生成代码定义的结构)。
- 服务器处理请求。
- 服务器发送消息(类型Reply或Exception)以启动响应。
- 服务器发送一个包含方法结果或异常的结构。
消息类型
在Thrift消息交换过程中,主要包括三种消息:Message、RequestStruct、ResponseStruct。
- Message: 一条Message主要包含Name、Message type、Sequence id。
- Name:指示请求调用的服务方法名。
- Message type:指示发送的消息类型。Message type有4种:
gotype TMessageType int32
const (
INVALID_TMESSAGE_TYPE TMessageType = 0
CALL TMessageType = 1 // 正常请求
REPLY TMessageType = 2 // 正常回复
EXCEPTION TMessageType = 3 // 异常回复
ONEWAY TMessageType = 4 // 单向请求,since Apache Thrift 0.9.3
)
- Sequence id:是由客户端分配的一个简单的消息ID。服务器将在响应消息中使用相同的序列 ID。客户端使用这个数字来检测无序响应。每个客户端都有一个 i32 字段,每条消息都会增加该字段。序列 id 在溢出时简单地环绕。
- RequestStruct: 跟在Call或Oneway类型Message后面的结构体,包含服务方法的参数。参数 ids 对应于字段 ids。结构的名称是附加了_args的方法的名称。对于没有参数的方法,发送一个没有字段的结构体。
- ResponseStruct: 跟在Reply类型消息后面的结构体,该结构体包含以下两个字段中的一个:
- 名称为success和 id 0 的字段,用于方法正常完成的情况。
- 异常字段、名称和 ID在 Thrift IDL 的服务方法定义中的throws子句中定义。
注意:RequestStruct和ResponseStruct跟我们平时编写的XxxRequest和XxxResponse不是一回事,确切的说,我们编写的XxxRequest和XxxResponse只是RequestStruct和ResponseStruct中的一个字段。
处理层接口
处理层接口是TProcessor:
gotype TProcessor interface {
Process(ctx context.Context, in, out TProtocol) (bool, TException)
// ProcessorMap returns a map of thrift method names to TProcessorFunctions.
ProcessorMap() map[string]TProcessorFunction
// AddToProcessorMap adds the given TProcessorFunction to the internal
// processor map at the given key.
// If one is already set at the given key, it will be replaced with the new
// TProcessorFunction.
AddToProcessorMap(string, TProcessorFunction)
}
在Thrift原生代码库中没有TProcessor的具体实现。具体实现是由Thrift编译器根据idl文件生成的。TProcessor会读取解码后的Message,根据Message信息找到对应的Handler(由我们程序员实现),将解码后的RequestStruct交给Handler处理,然后将Handler处理的结果封装成ResponseStruct,交由协议层编码后发送出去。
服务层/Server
服务器将上述所有各种功能汇集在一起:
- 创建传输层Transport
- 为传输创建输入/输出协议Protocol
- 创建基于输入/输出协议的处理器Processor
- 等待接入的connection并将它们交给处理器
服务层接口
gotype TServer interface {
ProcessorFactory() TProcessorFactory
ServerTransport() TServerTransport
InputTransportFactory() TTransportFactory
OutputTransportFactory() TTransportFactory
InputProtocolFactory() TProtocolFactory
OutputProtocolFactory() TProtocolFactory
// Starts the server
Serve() error
// Stops the server. This is optional on a per-implementation basis. Not
// all servers are required to be cleanly stoppable.
Stop() error
}
TServer在Java中有多种实现:
- 阻塞服务模型:TSimpleServer、TThreadPoolServer。
- 非阻塞服务模型:TNonblockingServer、THsHaServer和TThreadedSelectorServer。
在go语言中只有一个实现TSimplerServer,内部实现使用了Reactor网络IO模型:
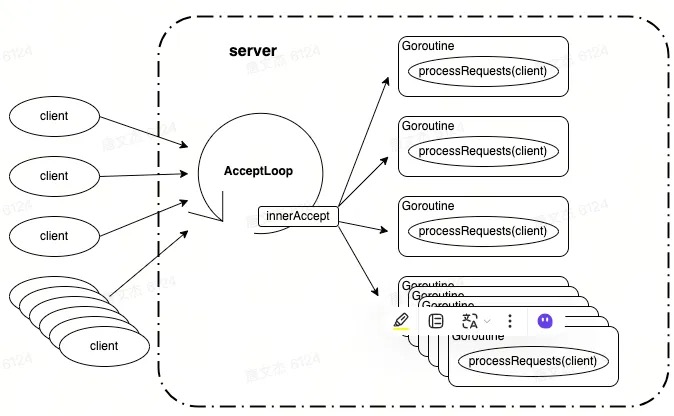
IDL和代码生成
IDL(Interface Definition Language)用于定义和生成跨语言的数据传输和服务接口。用户在IDL中声明自己的服务,然后通过Thrift编译将IDL生成服务端和客户端代码(可以为不同语言),从而实现服务端和客户端跨语言的支持。
优势
- 跨语言应用程序: 当你需要不同编程语言的应用程序之间进行数据交换和通信时,Thrift 提供了一种统一的解决方案,通过定义一次IDL文件即可生成多语言的代码。
- 分布式系统和微服务: 在构建大规模分布式系统或者微服务架构时,Thrift 的 RPC 支持和自动生成的服务代码能够极大地简化系统的开发和维护。
- 性能和效率要求高的场景: Thrift 生成的代码通常是经过优化的,能够提供高效的序列化和通信性能,适合于对性能要求较高的应用场景。
IDL
IDL 是Thrift 中用于定义数据结构和服务接口的语言。它类似于一种模式或规范,描述了:
- 数据结构:定义数据对象的字段、类型和结构。包括字段的名称、类型和顺序。这些数据结构可以是简单的基本类型(如整数、字符串等),也可以是复杂的结构体(struct)、枚举(enum)或集合(list、set、map)。
gostruct Person {
1: required i32 id;
2: required string name;
3: optional string email;
}
- 服务接口: 定义可以调用的方法、参数和返回类型。这使得你可以定义一组远程过程调用(RPC),从而实现分布式系统之间的通信。
goservice UserService {
void createUser(1: Person user),
Person getUserById(1: i32 userId),
void updateUser(1: i32 userId, 2: Person updatedUser),
void deleteUser(1: i32 userId)
}
在 Thrift 中,IDL 允许开发者定义复杂的数据结构和跨语言的服务接口,而无需关心底层实现细节。IDL 是平台无关的,这意味着你可以使用相同的定义来生成多种编程语言的代码,从而实现不同平台之间的数据交换和通信。 Thrift IDL语法可参考官方文档http://thrift.apache.org/docs/idl ,这里主要提几点常见误解的地方。
- Types 中 string 类型说明及正确使用:
- string按照协议要求(注意只是要求)需是UTF-8编码的字符串,所以请确认自己是UTF-8编码字符串再使用string类型;
- binary表示byte二进制数组,因此是字节数组情况下(比如json/pb序列化后数据在thrift rpc间传输)请使用binary类型,不要使用string类型;
- 比如Java和Python(使用utf8strings下)的生成代码就会验证string类型属性一定是UTF-8编码,但是Go生成代码因为没有严格验证,在Go里实现string/binary类型都使用string,但string底层只是字节数组没法保证是UTF-8编码的,所以会有坑。
- 字段是否必须
- Thrift其实在字段是否必须方面有三种语义:显示声明的required、optional,这两种如字面意思一样,表示该字段必填或者可选;还有一种隐藏的语义:当没有显示声明时候是默认(default),协议要求是写必填(required),读可选(optional),融合了两者语义,但是各种语义lib库实现上有差异,建议字段都显式声明required或者optional
代码生成
代码生成是指通过 Thrift 的IDL文件生成具体编程语言的代码,包括:
- 数据结构类: 对于每个定义的结构体或其他数据类型,Thrift 会生成相应的类或结构体定义。这些类包含字段的访问方法以及序列化和反序列化方法,使得数据可以在网络上传输或者存储到文件中。
- 服务端和客户端代码: 对于定义的服务接口,Thrift 自动生成服务端和客户端的代码。服务端代码包含每个方法的实现,以及接收请求、处理逻辑和发送响应的逻辑。客户端代码则包含方法的调用逻辑,使得客户端可以方便地远程调用服务端的方法。
生成的代码对于每种编程语言都是特定的,它们负责将 Thrift 的IDL文件翻译成目标语言所能理解和使用的形式。这样,开发者可以在各种不同的平台上使用 Thrift 生成的代码,实现跨语言的通信和数据交换,而无需手动编写复杂的序列化和网络通信代码。
序列化协议
序列化本质是把rpc的参数转换成一段连续的二进制流,还可以对参数进行压缩,使传输的流量更少。 thrift比较常见的序列化有2种: Binary序列化 和 Compact序列化,二者的区别是前者基本就是将参数顺序的写入连续的二进制流,后者对参数进行了一定的压缩。 序列化后的二进制流格式如下
powershell[id(2字节) + 类型标志(1字节) + 值] + [id(2字节) + 类型标志(1字节) + 值] + .....
由于二进制流中存在 id序号 和 类型flag,当server收到协议后,会根据服务端注册的idl, 根据 id序号到二进制流中找对应的buffer, 并会对类型做进一步比对。 Thrift提供了多种序列化协议,以满足不同的性能和存储需求,以下是对Thrift常用协议的详细解释:
Binary协议
Binary协议是一种二进制的序列化方式,具有高传输效率,但数据不可读。Binary协议采用TLV(Type-Length-Value)编码结构。 特点:
- TLV编码:每个字段都由TLV结构来描述,其中Type表示字段类型,Length表示字段长度,Value表示字段值。Value也可以是一个TLV结构,其中Type和Length的长度固定,Value的长度由Length的值决定。
- 扩展性:TLV编码结构简单清晰,扩展性较好。
- 内存开销:由于增加了Type和Length,可能会有额外的内存开销,特别是在大部分字段都是基本类型的情况下,可能会有不小的空间浪费。
Compact协议
Compact协议是一种二进制压缩序列化方式,与Binary协议相比,Compact协议在编码方式上进行了优化,以最大化节省空间开销。Compact协议在大部分字段的编码方式上与Binary协议保持一致。区别在于整数类型(i16、i32、i64三种类型)采用了先zigzag编码 ,再varint压缩编码实现
varint编码
不定长无符号整数编码,将整数类型由定长存储转为变长存储,减少空间浪费。每个字节,我们只使用低7位,最高的一位作为一个标志位(msb):
- 1:下一个byte也是该数字的一部分
- 0:下一个byte不是该数字的一部分
该编码好处在于对于小数采用更少字节,缺点在于对于大数,反而会比binary的空间开销更大。但大部分使用都是小数,整体来看,压缩作用较为明显。 举例,对i32类型的7进行编码,value值占4个字节,可以说前面3个字节都浪费了。
go00000000 00000000 00000000 00000111
而以i32类型的955为例,可以看出,由原来的4字节压缩到了2字节。 实现逻辑如下
gofunc PutUvarint(buf []byte, x uint64) int {
i := 0
for x >= 0x80 {
buf[i] = byte(x) | 0x80
x >>= 7
i++
}
buf[i] = byte(x)
return i + 1
}
func Uvarint(buf []byte) (uint64, int) {
var x uint64
var s uint
for i, b := range buf {
if b < 0x80 {
if i > 9 || i == 9 && b > 1 {
return 0, -(i + 1) // overflow
}
return x | uint64(b)<<s, i + 1
}
x |= uint64(b&0x7f) << s
s += 7
}
return 0, 0
}
zigzag编码
将有符号整数编码为无符号整数,使得负数的绝对值较小,解决了绝对值较小的负数经过varint编码后空间开销较大的问题(正数原码,负数补码)。假设有符号数直接采用varint编码,因为负数最高位是1,比如i32就都会使用5个字节了,反而使用更多字节,为了解决有符号负数问题,先采用zigzag编码将有符号数映射到无符号数上,
特点
- 变长编码:Zigzag编码可以将任意的有符号整数转换成无符号整数,使得可以用更少的比特来表示原本占用固定比特数的整数。这在数据压缩和序列化中尤为重要,可以减少存储空间和传输数据的大小。
- 处理负数:传统的整数表示方法(如二进制补码)不适合直接用于变长编码,因为负数会增加额外的比特以标识符号位。Zigzag编码通过将有符号整数映射到无符号整数空间中,有效地处理了负数的表示问题。
举例子,假设我们有一个有符号整数列表 [-5, 0, 3, -2, 7],我们希望对这些整数进行Zigzag编码。 原始整数表示:
go-5: 1011 (4比特的二进制补码表示)
0: 0000 (4比特的二进制补码表示)
3: 0011 (4比特的二进制补码表示)
-2: 1110 (4比特的二进制补码表示)
7: 0111 (4比特的二进制补码表示)
Zigzag编码的步骤:
- 对于负数,Zigzag编码将其映射成一个大的正数,使得变长编码更加高效。
- zigzag编码的映射规则是将负数映射到奇数,正数映射到偶数。具体地,有符号整数 n 被映射为 (n << 1) ^ (n >> 31)。
对于上面的例子:
go-5 映射为 9
0 映射为 0
3 映射为 6
-2 映射为 3
7 映射为 14
因此,Zigzag编码后的整数列表为 [9, 0, 6, 3, 14]。 这个编码过程可以保留整数之间的顺序,有效地减少了需要存储和传输的数据量,特别是在序列化和压缩整数数据时非常有用。
Json协议
JSON(JavaScript Object Notation)协议是一种轻量级的数据交换格式,易于人阅读和编写,也易于机器解析和生成。
SimpleJson协议
SimpleJSON 是一种简化的 JSON 协议,专注于简单的数据结构序列化和反序列化。它通常用于那些不需要完整 Thrift 功能的场景,比如快速原型开发或者对数据格式要求不严格的应用。
RPC简介
远程过程调用(简称RPC,英文为Remote Procedure Call)是一种计算机通信协议。通过该协议,程序可以在一台计算机上调用另一台计算机(通常是通过开放网络)的子程序,程序员在调用时无需额外编写交互代码,就像调用本地程序一样简单。RPC采用客户端-服务器(Client/Server)模式,经典的实现方式是通过发送请求和接受回应来进行信息交互。
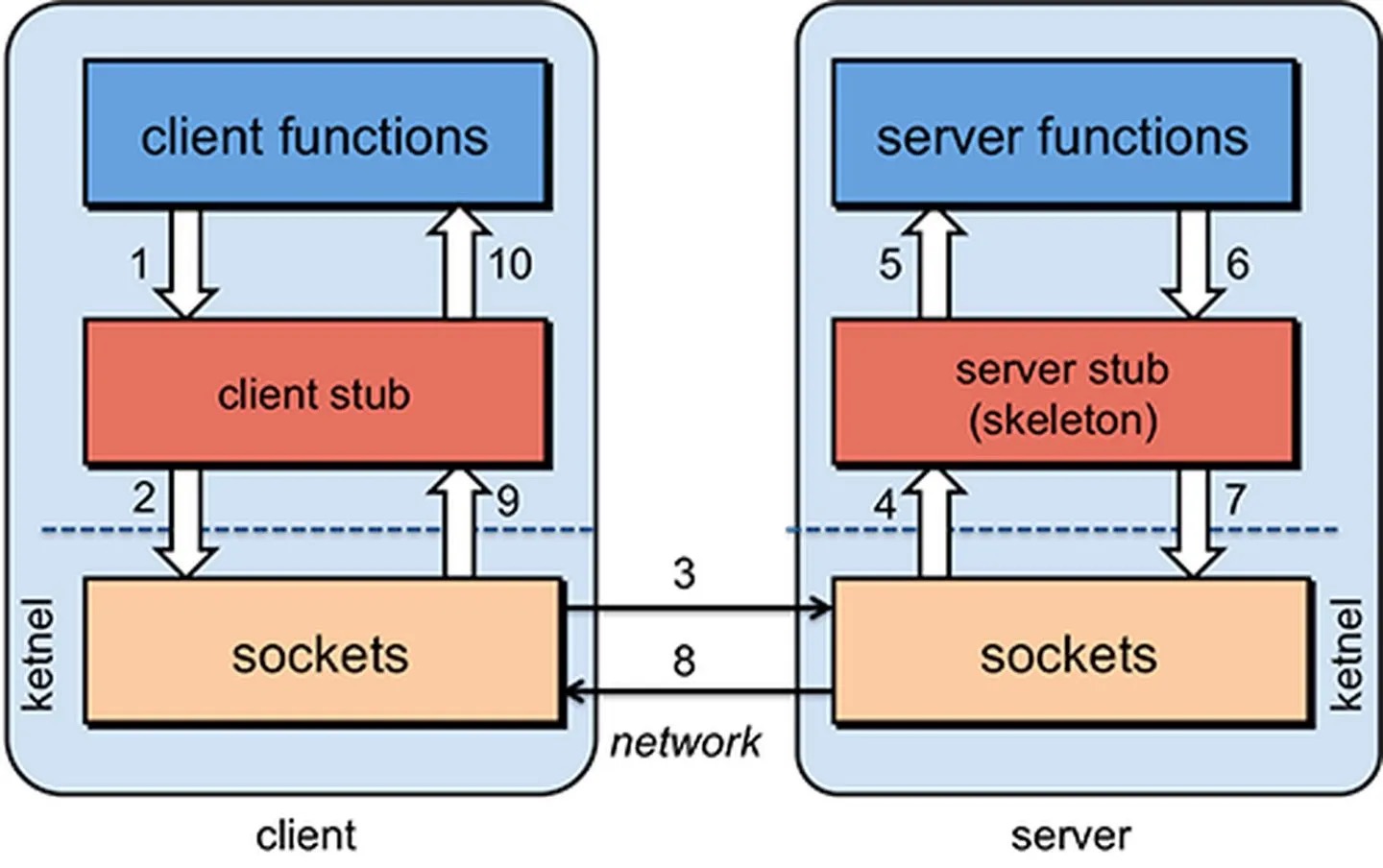
一般流程:
RPC(Remote Procedure Call,远程过程调用)一般的流程步骤如下:
- 客户端调用客户端stub(client stub):
- 客户端应用程序调用客户端stub(也称为代理或代理对象)。这个调用是在本地进行的,就像调用一个普通的本地函数一样。
- 调用参数被推送到栈(stack)中,准备进行后续的传输。
- 客户端stub将参数包装并发送到服务端机器:
- 客户端stub将调用参数进行序列化(也称为编组或marshalling),将其转换为适合网络传输的格式。
- 序列化后的参数通过系统调用发送到服务端机器。常见的序列化方式包括XML、JSON和二进制编码(如Thrift、Protocol Buffers等)。
- 客户端本地操作系统发送信息至服务器:
- 客户端本地操作系统负责将序列化后的信息通过网络传输到服务器。
- 传输可以使用自定义TCP协议、HTTP或其他传输协议。
- 服务器系统将信息传送至服务端stub(server stub):
- 服务器操作系统接收到来自客户端的信息后,将其传递给服务端stub。
- 服务端stub解析信息:
- 服务端stub将接收到的信息进行反序列化(也称为解组或unmarshalling),将其转换回原始的调用参数。
- 解析后的参数准备传递给实际的服务实现。
- 服务端stub调用程序并返回结果:
- 服务端stub调用实际的服务实现,传递解析后的参数,执行远程过程调用。
- 调用结果通过类似的方式返回给客户端。即,服务端stub将结果进行序列化,通过网络传输回客户端,客户端stub接收到结果后进行反序列化,并返回给客户端应用程序。
常见的RPC框架 这些框架在不同的场景和需求下有各自的优势,选择适合自己项目的RPC框架需要考虑到技术栈、性能需求、跨语言支持等因素。
- gRPC:由Google开发,基于HTTP/2协议,使用Protocol Buffers作为接口描述语言,支持多种语言,适合于高效的跨语言和跨平台的服务通信。
- Apache Dubbo:由阿里巴巴开发和维护的分布式服务框架,支持多语言、多协议,具有高性能和可扩展性,用于企业级微服务架构。
- Thrift:由Facebook开发,支持多语言、多平台,使用IDL定义接口,提供高性能的跨语言RPC通信,适合于大规模数据处理和分布式系统。
- Apache Avro:由Apache软件基金会开发,提供数据序列化和远程过程调用支持,使用JSON格式进行数据交换,适合于大数据系统和数据仓库。
- Spring Cloud:基于Spring框架的微服务套件,提供了REST和RPC调用的支持,包含服务发现、服务治理等模块,适用于构建云原生应用和微服务架构。
Thrift、RPC、IDL三者的关系
为了进一步理解Thrift、RPC和IDL三者之间的关系,我们回顾下它们各自的功能和定义,探讨它们在分布式系统中的角色和相互作用。
- Thrift:Thrift 是一个跨语言的远程服务框架,它提供了一种简单且高效的方法来定义数据类型和服务接口,并自动生成多种编程语言的代码,包括数据结构定义、客户端和服务端的远程调用代码。
- RPC:RPC 是一种通信机制,用于实现不同计算机系统之间的远程调用。它允许一个程序(称为客户端)调用另一个程序(称为服务端)的过程或函数,就像调用本地的函数一样,但实际上是通过网络来实现的。RPC 在分布式系统中起到了关键作用,简化了跨网络节点之间的通信。
- IDL:IDL 是一种特定于 Thrift 的语言,用于描述数据结构和服务接口。它允许开发者定义数据类型和服务方法的结构、参数和返回类型,而不必考虑底层的通信细节。IDL 文件是 Thrift 自动生成代码的基础,通过它可以生成不同编程语言的数据结构定义和服务接口实现。
关系: Thrift vs RPC:
- Thrift 是一个框架,实现了 RPC 的概念,提供了跨语言的远程服务能力。它不仅定义了服务接口和数据结构(通过IDL),还生成了客户端和服务端的具体实现代码。
- RPC 是一种通信模式,用于实现远程过程调用。它可以通过不同的实现(如Thrift、gRPC等)来实现远程服务调用。
Thrift vs IDL:
Thrift 包含了 IDL 的概念,即用于描述数据结构和服务接口的语言。Thrift 使用自己的IDL来定义服务接口和数据类型,然后生成对应的代码。 IDL 本身是一种语言中立的接口描述语言,用于定义接口的规范和结构,以便于在不同语言和平台之间进行通信。 RPC vs IDL:
RPC 是一种通信协议和模式,IDL 是用于描述接口和数据结构的语言。RPC 实现了IDL中定义的接口,通过序列化和网络传输来进行远程调用。 综上所述,Thrift 是一个具体的框架和工具集,它使用IDL来定义服务接口和数据结构,并实现了RPC的通信模式,使得开发者能够在分布式系统中方便地进行跨语言和跨平台的远程服务调用。
本文作者:sora
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!