目录
引言
在介绍函数式编程之前,我们先来看下函数在JS中的作用。在JS中,函数是一等公民,除了传统函数的使用,它可以作为普通变量一样作为函数参数,还可以在函数中被返回。除此之外,函数还可以当做类来使用,我们使用new加上函数就可以构造一个实例,并且子类还可以通过构造函数的prototype属性实现原型继承。在React中,组件其实也是一个函数。所以在JS中,函数无处不在。
在软件开发中,我们常见的编程形式有命令式编程和声明式编程。而函数式编程是一种较为抽象的编程方式,是一种强调以函数为主要开发风格的编程方式。在函数式编程中,我们以函数的形式思考和编程。
下面,我们简单来看下命令式编程和声明式编程的区别。
- 例子1
javascript// 命令式方式
var arr = [0, 1, 2]
for(let i = 0; i < array.length; i++) {
arr[i] = arr[i] * 2
}
arr; // [0, 2, 4]
// 声明式方式
arr.map(num => num *2)
- 例子2
javascript// 命令式方式
document.getElementById('#root').innerHTML = '<div>根节点</div>'
// 声明式方式
function insertMsg(domId, msg, format) {
if (!domId) return;
document.querySelector(domId).innerHTML = `<${format}>${msg}</${format}>`
}
insertMsg('#root','根节点','div')
可以看到,命令式的方式很具体的告诉计算机如何执行某个任务,先做什么再做什么。而声明式的方式主要思想是告诉计算机应该做什么,但不指定具体要怎么做。函数式编程和声明式编程很像,因为他们思想是一致的:即只关注做什么而不是怎么做。但函数式编程不仅仅局限于声明式编程。
**总结:**这种命令式的写法比较简单,也最容易想到,开发起来很快。缺点显而易见,程序的复用性很差。如果我们有很多类似的这种操作,这就有问题了。函数式编程优点如下。
-
扩展性:可以通过增加一些额外的代码,而不用修改之前的逻辑来实现功能的扩展
-
模块化:代码高度解耦,互不影响
-
重用性:可以相互使用,实现重用
-
抽象性:隐藏了很多实现的细节
-
易测试:很容易看出是哪部分代码出了问题
分类
高阶函数
高阶函数是对其他函数进行操作的函数。满足下列条件之一的函数即可称之为
- 接受一个或多个函数作为参数
- 输出一个函数
举例,最常见的是数组内置的一些方法,map和forEach,参数就是一个函数。
高阶函数的优势很明显。下面的例子一目了然。
javascript// 不使用用高阶函数
const arr1 = [1, 2, 3, 4, 5];
let arr2 = [];
for (let i=0; i<arr1.length; i++) {
if (arr1[i]>3) {
arr2.push(arr1[i]);
}
}
console.log(arr2); // [4,5]
// 使用filter
let arr3 = arr1.filter((ele, index, self) => {
return ele > 3;
});
console.log(arr3);
应用
一、柯里化(curring)
柯里化又称部分求值。一个柯里化的函数首先会接受一些参数,接受了这些参数之后,该函数并不会立即求值,而是继续返回另外一个函数,刚才传入的参数在函数形成的闭包中被保存起来。待到函数中被真正的需要求值的时候,之前传入的所有参数被一次性用于求值。
柯里化是函数式编程的一个重要技巧,将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
javascript// 用闭包把传入参数保存起来,当传入参数的数量足够执行函数时,就开始执行函数
function curry(fn) {
// 如果传入的函数只有一个参数,直接返回该函数
if (fn.length <= 1) return fn;
const generator = (...args) => {
// 判断当前参数长度够不够,参数够了就立马执行
if (fn.length === args.length) {
return fn(...args)
} else {
return (...args2) => {
return generator(...args, ...args2)
}
}
}
return generator
}
let add = (a, b, c, d) => a + b + c + d
const curryiedAdd = curry(add);
curryiedAdd(1)(2)(3)(4)
很多同学知道柯里化的原理,但是不了解它具体在实际编程中的运用。
下面我举几个例子。
- 例子1,关于网络请求
javascript// 常见的写法
function fetch(type,url,data){
let xhr = new XMLHttpRequest();
xhr.open(type, url);
xhr.send(data);
}
// 虽然很通用,但是还是有一些重复代码,而且get和post也不是一眼能区分
fetch('get', 'www.test.com', '');
fetch('post', 'www.test.com', 'num=10')
// 使用curry
let fetch = curry(fetch)
// 所有post类型的请求都可以使用这个方法
let post = fetch('post');
// 所有xx接口的post类型的请求都可以使用这个方法
let postTest = post('www.test.com');
postTest('num=10')
- 例子2,关于JS类型判断
javascript// 使用对象原型方法toString可以判断几乎所有数据类型
let isString = obj => Object.prototype.toString.call( obj ) === '[object String]';
let isRegExp = obj => Object.prototype.toString.call( obj ) === '[object RegExp]';
// 还是一样的的问题,会有很多重复的代码部分,可以抽象出一些重复的部分
const isType = type => target => `[object ${type}]` === Object.prototype.toString.call(target);
const isArray = isType('Array');
isArray([])
- 例子3,bind的实现
javascript// bind简化实现,原理就是利用柯里化实现延迟计算
// 使用es6语法实现起来非常简洁
Function.prototype.bind = function (context, ...args) {
let fn = this;
return (...otherArgs) => {
return fn.apply(context, [...args, ...otherArgs] );
}
}
let obj = {
name: 'abc'
}
const myfun = function(x, y) {
console.log(this.name);
}
let bindmyfun = myfun.bind(obj);
bindmyfun();
总结: 通过上面的例子,我们得出柯里化的主要作用就是延迟计算,参数复用。
二、惰性加载
惰性加载表示函数执行的分支仅会发生一次。举例,如果做PC开发的时候,我们通常需要对不同的浏览器进行事件监听和移除的方法的一个兼容。
下面是正常的写法。
jslet addEvent = function(ele, type, fn) {
if (window.addEventListener) {
return ele.addEventListener(type, fn, false);
} else if (window.attachEvent) {
return ele.attachEvent('on' + type, function() {
fn.call(ele);
});
}
};
但是,每次在使用这个方法的时候都会执行if else这个判断,其实对于同一个浏览器而言,只需要判断一次环境就可以了。
- 解决方案1
我们在函数被调用的时候重载函数。
javascriptlet addEvent = function(ele, type, fn) {
if (window.addEventListener) {
addEvent = function(ele, type, fn) {
ele.addEventListener(type, fn, false);
}
} else if (window.attachEvent) {
addEvent = function(ele, type, fn) {
ele.attachEvent('on' + type, function() {
fn.call(ele)
});
}
}
addEvent(ele, type, fn);
};
- 解决方案2
我们在声明函数时就指定适当函数。这样,第一次调用函数就不会损失性能了,而在代码首次加载时会损失一点性能
javascriptlet addEvent = (function() {
if (window.addEventListener) {
return function(ele, type, fn) {
ele.addEventListener(type, fn, false);
}
} else if (window.attachEvent) {
addEvent = function(ele, type, fn) {
ele.attachEvent('on' + type, function() {
fn.call(ele)
});
}
}
})();
以上两种方式都只在第一次执行函数时做了性能检测,省去了后续调用时多余的操作,优化了性能。
三、函数节流和防抖
我们都知道在scroll,suggest这样的场景下,函数会被频繁的触发,这样很消耗性能,会造成浏览器的卡顿。
比较好的解决方案就是控制函数被触发的频率,也就是函数节流了。
节流的定义:如果你持续触发事件,每隔一段时间,只执行一次事件。
节流的原理很简单:利用setTimeout和闭包。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
下面介绍的这种方法利用的是定时器的这种形式
javascript// 超级简易版
function throttle(func, wait) {
let timeout;
return function(...args) {
let context = this;
if (!timeout) {
timeout = setTimeout(function(){
timeout = null;
func.apply(context, args)
}, wait)
}
}
}
纯函数
纯函数的特征如下。
- 只依赖于它的参数,同时对于任何相同的输入有着相同的输出结果。
- 不对外产生副作用
如何理解?
首先来解释第一点:函数的返回结果只依赖于它的参数
javascript// 非纯函数
// 返回结果依赖外部变量a,a的值是不确定的,不能保证相同的输入有相同的结果
const a = 1;
const fun1 = (b) => a + b
// Math.random()产生一个随机数,所以返回结果也不确定
const fun2 = (x) => Math.random() + x
// 纯函数
const fun3 = (x) => x * 2
接下去说一下第二点:副作用是指:在计算结果的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。比如说调用 DOM API 修改页面,或者你发送了 Ajax 请求,改变参数或者外部变量的值,还有调用 window.reload 刷新浏览器都是副作用的一种表现。
javascript// 非纯函数
// 改变了外部变量a
let a = { num: 11};
function set(x) {
x.num++;
return x;
}
set(a)
// 纯函数
let a = { num: 11};
function set(x) {
let b = {...x};
b.num ++;
return b;
}
set(x)
我们看到纯函数的输出结果是一致的,可预测的,相同的输入会有相同的返回值。
为什么使用纯函数?看下面的例子
javascriptlet num = 0
function increment() {
return ++num;
}
这个函数读取了外部的变量,可能会觉得这段代码没有什么问题,但是我们要知道这种依赖外部变量来进行的计算,计算结果很难预测,你也有可能在其他地方修改了 num 的值,导致你 increment 出来的值不是你预期的,而且你多次调用这个函数返回的结果是不一样的,这样造成的结果就是很难定位到问题发生的原因和位置。
应用
最常见的应用就是redux中的reducer。reducer必须是一个纯函数,它会接受一个当前的state和action作为参数,返回一个全新的state,但是不能在原有的state基础上修改。
所以我们常常会见到这样的处理方式
javascriptreturn Object.assign({}, state, ...x);
return {...state,...x}
那如果我们直接在state上修改,会造成什么结果呢?结果就是页面不会触发重渲染。
所以这就是为什么要求reducer必须是一个纯函数呢,不能修改外部变量。
下面是redux中combineReducers函数的部分源码截图

可以看到在代码中,我们通过对比旧的state对象和新的state对象的地址指针,来决定状态标志位hasChanged是true还是false,从而决定返回的新或旧的state。所以,如果我们直接改变旧state的属性,那preState肯定是等于nextState。
Redux通过对比新旧对象的存储位置是不是一样,来决定state是不是发生了变化。
为什么这样设计呢?答案很简单,性能好。试想一下,如果state层级很深,而我们不是简单的通过preState===nextState来判断state是不是发生变化,那我们唯一的方式就是深对比,通过不断遍历对象,然后通过递归,复杂度可想而知。
总结
-
可复用性:纯函数仅依赖于传入的参数,这意味着你可以随意将这个函数移植到别的代码中
-
可测试性:纯函数非常容易进行单元测试,因为不需要考虑上下文环境,只需要考虑输入和输出。
-
并行代码:纯函数是健壮的,改变执行次序不会对系统造成影响,因此纯函数的操作可以并行执行。
最终目的是:让你的代码尽可能简单易懂和灵活。
函数组合
函数组合是一个数学概念,允许你将两个或更多个函数组合到一个新函数中,就像搭积木一样,最后用一个函数实现所有函数的功能。
例如,我们有这样一个需求。输入一个字符串,过滤掉两遍的空格,全部转为大写,重复三遍,最后格式化一下,插入到指定dom中。
于是,我们就开始写代码了
javascriptlet str = 'angle';
function handleStr(x) {
x = x.replace(/^(\s*)|(\s*)$/g,'');
x = new Array(4).join(x);
let html = `<h1>i am ${x}</h1>`
document.getElementById('#root').innerHTML = html
}
如果有一天,我们还有另外一个业务。不需要过滤空格,格式化为div,重复五遍,最后插入到anotherDom中。于是又写了下面这个函数。
javascriptfunction handleStr(x) {
x = new Array(6).join(x);
let html = `<div>i am ${x}</div>`
document.getElementById('#anotherDom').innerHTML = html
}
缺点显而易见了吧。代码冗余,不好理解,很难复用。
所以,如果我们这样写,是不是会优雅很多。
javascriptconst trim = (x) => x.replace(/^(\s*)|(\s*)$/g,'');
const repeat = (n, x) => new Array(n + 1).join(x);
const format = (format, x) => `<${format}>i am ${x}</${format}>`
const insertMsg = (domId, x) => {
if (!domId) return;
document.querySelector(domId).innerHTML = x
}
// 这边需要利用curry函数将多个参数的函数进行柯里化
const handleStr = compose(curry(insertMsg)('#root'), curry(format)('h1'), curry(repeat)(3), trim);
那compose函数到底是如何实现的呢
javascript// 我的实现方式,比较low,但是比较容易看懂
function compose(...funcs) {
return (...args) => {
let res = funcs[funcs.length-1](...args)
for (let i = (funcs.length-2); i>=0; i--) {
res = funcs[i](res)
}
return res;
}
}
// redux的实现
function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
// underscore的实现
function compose() {
var args = arguments;
var start = args.length - 1;
return function() {
var i = start;
var result = args[start].apply(this, arguments);
while (i--) result = args[i].call(this, result);
return result;
};
};
函数记忆
函数记忆是指将上次的计算结果缓存起来,再次调用的时候如果遇到相同的参数,就直接返回缓存中的结果。
比如下面这样
javascriptlet add = (x, y) => x + y;
// 我们实现这样一个函数
add = memory(add);
add(1,2);
// 相同的参数,第二次调用的时候直接从缓存中取出数据,而非重新计算
add(1,2)
下面我们来实现以下
javascriptconst memory = function (fn) {
let cache = {};
return function(...args) {
// 根据参数生成一个唯一的key,这个key的生成方式还有待研究,不够严谨
let key = args.join('&');
// 如果key命中缓存,说明已经计算过该函数,则直接返回缓存结果
if (cache.hasOwnProperty(key)) {
return cache[key]
}
cache[key] = fn.apply(this, args);
return cache[key];
}
}
下面测试一下使用效果
javascriptlet multiply = (x, y, z) => x*y*z;
let memoryMultiply = memory(multiply);
console.time('memory')
for (let i=0; i<10000; i++) {
memoryMultiply(1,2,3)
}
console.timeEnd('memory')
console.time('not memory')
for (let i=0; i<10000; i++) {
multiply(1,2,3)
}
console.timeEnd('not memory')
在chrome控制台运行上面的程序,结果如下,出乎意料的是使用函数记忆居然比不使用要慢了很多。我自己只能理解为,这种简单计算的时间其实比去缓存中存取来得更快。那到底什么场景使用这个呢。我认为是复杂计算或者递归的场景。

我们来看下著名的斐波那契数列。
javascriptlet count = 0;
let fibonacci = function(n) {
count++;
return n < 2? n : fibonacci(n-1) + fibonacci(n-2);
};
// 使用普通递归
console.time('not memory')
fibonacci(20);
console.timeEnd('not memory');
console.log('计算次数', count)
// 使用函数记忆
// 注意这边要覆盖自身
count = 0;
fibonacci = memory(fibonacci);
console.time('memory')
fibonacci(20);
console.timeEnd('memory');
console.log('计算次数', count)
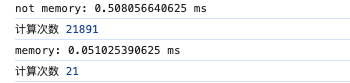
可以看到函数真正执行计算的次数和时间大大减少,这就是使用函数记忆的优势了。
总结: 函数记忆只是一种编程技巧,memory函数本质上它也属于一种高阶函数。从上面的例子看得出来,并不是所有场景都适用于这种方式。而且这种方式还有一个缺点是牺牲算法的空间复杂度。所以,最适合业务场景的才是最好的。
本文作者:sora
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!