目录
Coze 是在 GPT 大模型之上AI Agent方向中的产品。它可以用来开发新一代 AI Chat Bot 的应用编辑平台,无论你是否有编程基础,都可以通过这个平台来快速创建各种类型的 Chat Bot,并将其发布到各类社交平台和通讯软件上。在此之前,开发者通常需要使用OpenAI提供的GPT OpenAPI来实现多轮对话、prompt预加载、私有知识库和调用自研接口等功能,成本较高。如今有了Coze这类Agent Framework,用户无需编程技能,仅需5分钟即可构建并发布一个自己的Bot。
什么是AI Agent
LLM作为推理引擎的能力不断增强,AI Agent框架为其提供了结构化思考的方法。软件生产正逐渐进入“3D打印”时代,可以根据用户需求进行个性化定制。Agent框架的目标是打造每位知识工作者信赖的AI工作伙伴,所以我们认为Agent产品需要具备一定的干预空间。目前实践中最具代表性的是两类Agent:中间层的Agent Framework和垂直领域的Vertical Agent。前者允许行业专家为自己创建Agent工作伙伴和工作流分身,使组织更加精简;后者专注于深耕某一领域的最佳实践,收集高质量的专有工作流数据。Coding Agent则是这两个方向的结合,具有潜力成为未来所有Agent与人类之间的翻译官。
一段网上对于AI Agent方向的描述,来源虎嗅《千亿美元AI Agent赛道,如何重构知识工作?》
向量化
在计算机领域,现实问题通常被转换成数学问题,因为计算机底层基于二进制系统,全是0和1。为了让数学问题具备“智能”,需要使用的一项关键技术就是向量化。这里简单做个科普,不做过多深入剖析(其实lz也只知皮毛)。
图片向量化
图像向量化是指将图像转换为由矢量组成的数学表示形式的过程。它通常用于创建可缩放、可编辑且易于存储的图像。
图片特征向量是图像处理和计算机视觉领域中的一个重要概念。它将图片的内容转换为一个高维向量,这个向量可以用来描述图片的各种特征,如颜色、纹理、形状等 特征向量的生成方式
- 颜色特征:
- 颜色直方图:统计图片中每种颜色出现的频率。
- 颜色空间转换:将图片从RGB颜色空间转换到其他颜色空间(如HSV、Lab),然后提取特征。
- 纹理特征:
- 灰度共生矩阵:描述图片中灰度级别的共生关系。
- 局部二值模式(LBP):捕捉图片的局部纹理信息。
- 形状特征:
- 边缘检测:使用Sobel、Canny等边缘检测算法提取图片的边缘。
- 轮廓描述:使用Hu矩、傅里叶描述子等方法描述图片的轮廓。
- 深度学习特征:
- 卷积神经网络(CNN):使用预训练的CNN模型(如VGG、ResNet)提取高层次的图片特征。
提取方式:提取图片特征向量的方法有很多,常见的是 SIFT 和 SURF 两种常用的算法
其中,最常用的软件之一是OpenCV(Open Source Computer Vision Library),它是一个基于开源发行的跨平台计算机视觉和机器学习软件库,它支持多种编程语言,包含了数百种图像处理和计算机视觉算法。

| 转化方式 | 例子 |
|---|---|
| 特征向量 | [1, 3, 2, 1, 9, 10, 99, 0, 30 ...] |
| [姓名,年龄,头发,身高,收入。。。] |
文本向量化
文本向量化是将文本数据转换为数值向量的过程,在自然语言处理(NLP)领域,文本向量化是一个基础步骤。
词向量化将词转为二进制或高维实数向量,句子和文档向量化则将句子或文档转为数值向量,通过平均、神经网络或主题模型实现。
人类传下来的所有发展成果都浓缩到文字当中了,理解了自然语言,就可以理解整个人类文明成果,可以和 人类无缝交流->才有可能实现通用的人工智能
以下是几种常见的词向量化方法:
词向量化
独热编码(One-Hot Encoding)
独热编码是一种将分类数据(如文本中的单词或类别标签)转换为二进制向量的方法。每个类别标签都被表示为一个长度为 N 的向量,其中 N 是类别的总数。在这个向量中,只有一个位置的值为 1,其余位置的值为 0。这种标签是一种高维稀疏向量。 创建步骤:
- 确定类别总数:首先确定需要编码的所有类别的总数。
- 创建向量:对于每个类别,创建一个长度为 N 的向量,其中只有一个位置的值为 1,其余位置的值为 0。
示例 假设我们有以下类别标签:["cat", "dog", "fish"]。
- 确定类别总数:类别总数为 3。
- 创建向量:
- "cat" 被表示为 [1, 0, 0]
- "dog" 被表示为 [0, 1, 0]
- "fish" 被表示为 [0, 0, 1]
尽管 One-Hot Encoding 在许多应用中非常有用,但它的高维度性、无法捕捉语义信息、数据稀疏性、扩展性差以及无法处理未见过的类别等缺点限制了其在某些任务中的应用
词袋模型(Bag of Words)
词袋模型是一种简单且常用的文本表示方法。它将文本表示为词汇表中各个单词的频率。只计每个词出现的次数。文本转换出来的向量会是一个长长的数字列表,每个数字对应文档中出现某个词的频率。主要步骤包括
- 构建词汇表:提取所有文档中的所有不同单词。
- 生成词频向量:统计每个文档中每个单词的出现次数。
例子:
句子1:“我喜欢坐高铁回家”;句子2:“中国高铁非常快”。
句子1分词:“我、喜欢、坐、高铁、回家”;
句子2分词:“中国、高铁、非常、块”。
根据上述两句出现的词语,构建一个字典:{“我”:1,“喜欢”:2,“坐”:3,“高铁”:4,“回家”:5,“中国”:6,“非常”:7,“快”:8}
该字典中包含8个词,每个词都有唯一索引,并且它们出现的顺序是没有关联的,根据这个字典,我们将上述两句重新表达为两个向量: 句子1:[1,1,1,1,1,0,0,0]
句子2:[0,0,0,1,0,1,1,1]
这两个向量共包含8个元素,其中第 i 个元素表示字典中第 i 个词语在句子中出现的次数。在文本检索和处理中,可以通过该模型很方便的计算词频。该方法虽然简单,但却存在着三个大问题:
- 维度灾难:很明显,如果上述的字典中包含了9999个词语,那么每一个文本都需要用9999维的向量才能表示,如此高维度的向量很需要很大的计算力。
- 无法利用词语的顺序信息。
- 存在语义鸿沟的问题。
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是一种改进的词袋模型,基于词频的加权文本向量化方法。它不仅考虑单词在文档中的频率,还考虑单词在整个语料库中的逆文档频率,以减少常见但无意义单词的影响。
一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比,如果一个词在很多文档都出现,那可能重要性就没有那么高,比如"了"、"的"这类词。这种方法可以捕捉单词的重要性,但仍然不能捕捉单词之间的语义关系。
TF-IDF在信息检索、文本分类和自然语言处理等领域有广泛的应用
计算步骤:
- 计算TF(词频):单词在文档中出现的频率。

- 计算IDF(逆文档频率):单词在整个语料库中出现的稀有程度。

- 计算TF-IDF:TF与IDF的乘积。
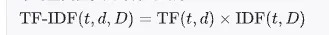
词嵌入(Word Embeddings)
词嵌入是将单词表示为低维实数向量的方法,能够捕捉单词之间的语义关系。常见的词嵌入方法包括Word2Vec、GloVe和FastText。
这里介绍下Word2Vec,这是一种基于神经网络的文本向量化方法。它通过将单词映射到一个高维向量空间中,使得在语义上相似的单词在向量空间中也相互接近。它的主要目标是捕捉单词之间的语义关系,并将其表示为实数向量。它主要有两种训练方式:CBOW 和 Skip-gram。
- CBOW(Continuous Bag of Words):
- 目标:通过上下文单词预测中心单词。
- 方法:给定上下文单词,最大化中心单词的概率。
- 优点:计算效率较高。
- Skip-gram:
- 目标:通过中心单词预测上下文单词。
- 方法:给定中心单词,最大化上下文单词的概率。
- 优点:在小数据集上表现更好,并且能够捕捉更多的语义信息。
示例 假设我们有一句话:“I love natural language processing”。 CBOW:给定上下文单词“love”和“language”,预测中心单词“natural”。 Skip-gram:给定中心单词“natural”,预测上下文单词“love”和“language”。
应用 在许多NLP任务中有广泛应用,比如
- 文本分类:垃圾邮件检测、情感分析等。
- 信息检索:搜索引擎中的文档检索。
- 机器翻译:将源语言单词映射到目标语言单词。
- 问答系统:理解问题并生成答案。
句子向量化
句子向量化是将整个句子表示为一个固定维度的实数向量。
大规模语言模型(LLM)是深度学习的一个重要成果,它们通过训练大规模的神经网络来学习语言的表现形式。这些模型已经取代了传统的文本处理方法,成为自然语言处理领域的主流技术。例如,OpenAI的GPT-3和Google的BERT等模型都是基于LLM的架构。
简单平均/加权平均
对句子中的词向量进行平均或根据词频进行加权平均。
递归神经网络(RNN)
通过递归地处理句子中的每个词来生成句子表示。使用LSTM或GRU等递归神经网络处理句子中的每个词,生成句子表示。
卷积神经网络(CNN)
使用卷积层来捕捉句子中的局部特征,然后生成句子表示。
自注意力机制(如Transformer)
Word2Vec 2013年就被Google提出来了,为什么2023年大模型才出来?。在文本处理领域的深度学习基本上都是RNN(循环神经网络),但是RNN缺点的在于在预测的时候较近的一些词的权重比较高,如果要全部关注信息,量太大算不动。2017年Google发表Transformer框架,其中提出了自注意力机制:Attention isAllYouNeed,解决了自然语言特征提取的问题。
自注意力机制(Self-Attention Mechanism)是Transformer模型的核心组件,它能够捕捉句子中不同位置的单词之间的依赖关系。自注意力机制通过计算每个单词与其他单词之间的相关性来生成句子的表示。Transformer模型利用多头自注意力机制来增强模型的表达能力。
自注意力机制赋予了Transformer两个关键属性:
- 它们学习的嵌入空间在语义上是连续的,即在嵌入空间中稍微移动一点,只会稍微改变相应标记的面向人类的含义。word2vec空间也验证了这一属性。
- 它们学习的嵌入空间在语义上是可插值的,即在嵌入空间中两点之间取中间点会产生一个代表相应标记之间“中间含义”的点。这是因为每个新的嵌入空间都是通过对前一个空间中的向量进行插值来构建的。
自注意力机制的基本概念
- 查询(Query, Q):表示对其他单词的查询。
- 键(Key, K):表示被查询的单词。
- 值(Value, V):表示查询的结果。
自注意力的计算步骤
- 计算查询、键和值:
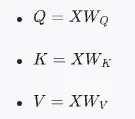
- 计算注意力权重:

- 多头注意力:将多个注意力头的结果连接起来,并通过一个线性变换。
Transformer模型
Transformer模型由编码器和解码器组成,每个编码器和解码器层都包含多头自注意力机制和前馈神经网络。
Transformer模型中采用了 encoer-decoder 架构,但其结构相比于Attention更加复杂,论文中encoder层由6个encoder堆叠在一起,decoder层也一样。
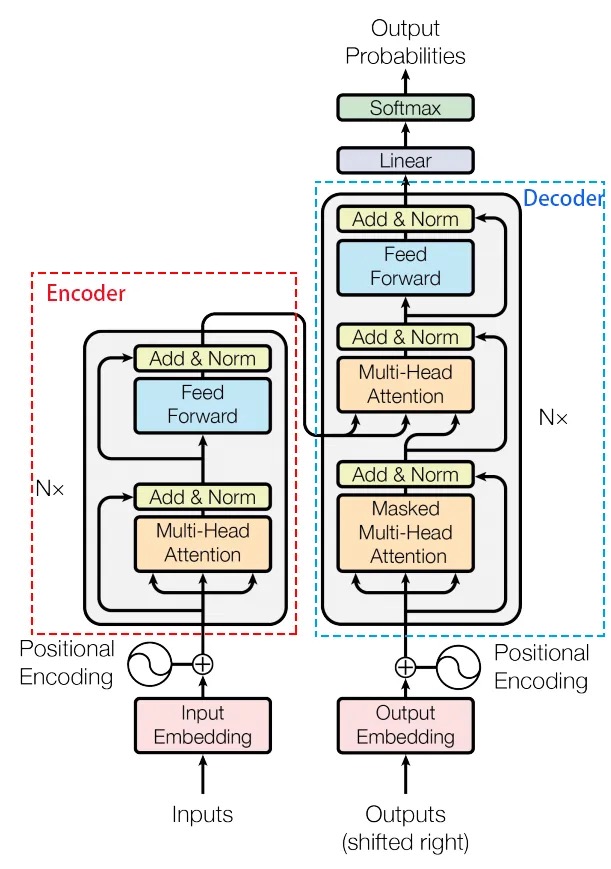
- 编码器(Encoder):由多个相同的层堆叠而成,每层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention Mechanism): 自注意力层负责学习词与词之间的依赖关系。
- 前馈神经网络(Feed-Forward Neural Network):前馈神经网络层负责对每个词进行非线性变换。
- 解码器(Decoder):由多个相同的层堆叠而成,每层包含三个子层:
- 多头自注意力机制(Masked Multi-Head Self-Attention Mechanism):解码器的自注意力层负责学习词与词之间的依赖关系,以及词与编码器输出之间的依赖关系。
- 多头注意力机制(Multi-Head Attention Mechanism): 编码器-解码器注意力层负责将编码器输出的信息传递给解码器。
- 前馈神经网络(Feed-Forward Neural Network): 解码器的前馈神经网络层负责对每个词进行非线性变换。
BERT 使用BERT模型进行句子向量化的步骤如下
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer的预训练模型,它通过自注意力机制生成句子的向量表示。BERT利用双向编码器来捕捉句子中每个单词的上下文信息。
- 加载预训练模型和分词器:使用 BertTokenizer 和 BertModel 加载预训练的BERT模型和分词器。
- 转换句子格式:使用分词器将句子转换为BERT模型的输入格式,包括分词、添加特殊标记(如 [CLS] 和 [SEP])以及生成输入张量。
- 获取模型输出:将输入张量传递给BERT模型,获取模型的输出,包括最后一层的隐藏状态。
- 提取句子向量:提取 [CLS] 标记的向量表示,作为句子的向量表示。
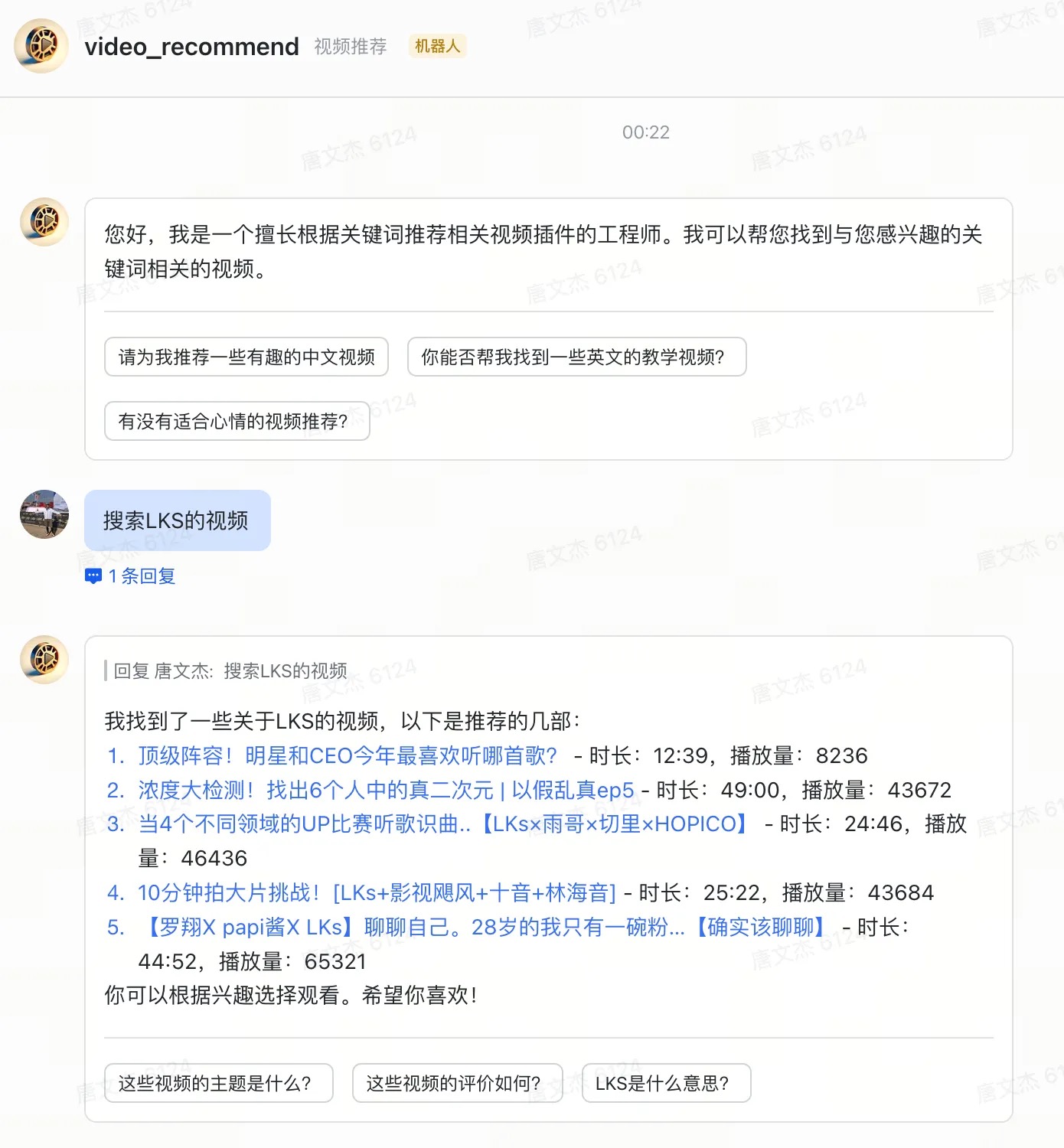
交互效果
通过coze搭建了一个视频推荐/搜索的飞书机器人(默认发布后只有自己可见,可以在飞书开放平台设置权限),效果如下。
相比之前复杂的飞书机器人发布流程(去开放平台注册应用、配置事件回调、开通权限等),现在只要在发布机器人前授权飞书就可以一键完成发布
搭建过程
一、创建Bot
点击首页左上方的Create bot,会跳出弹窗,你需要先选择Workspace。我这里是点击了侧边栏的Personal,然后再去创建。
系统默认创建了一个 Personal 的个人团队,该团队内创建的资源例如 Bot、插件、知识库等无法分享给其他团队成员。你也可以创建团队或加入其他团队。
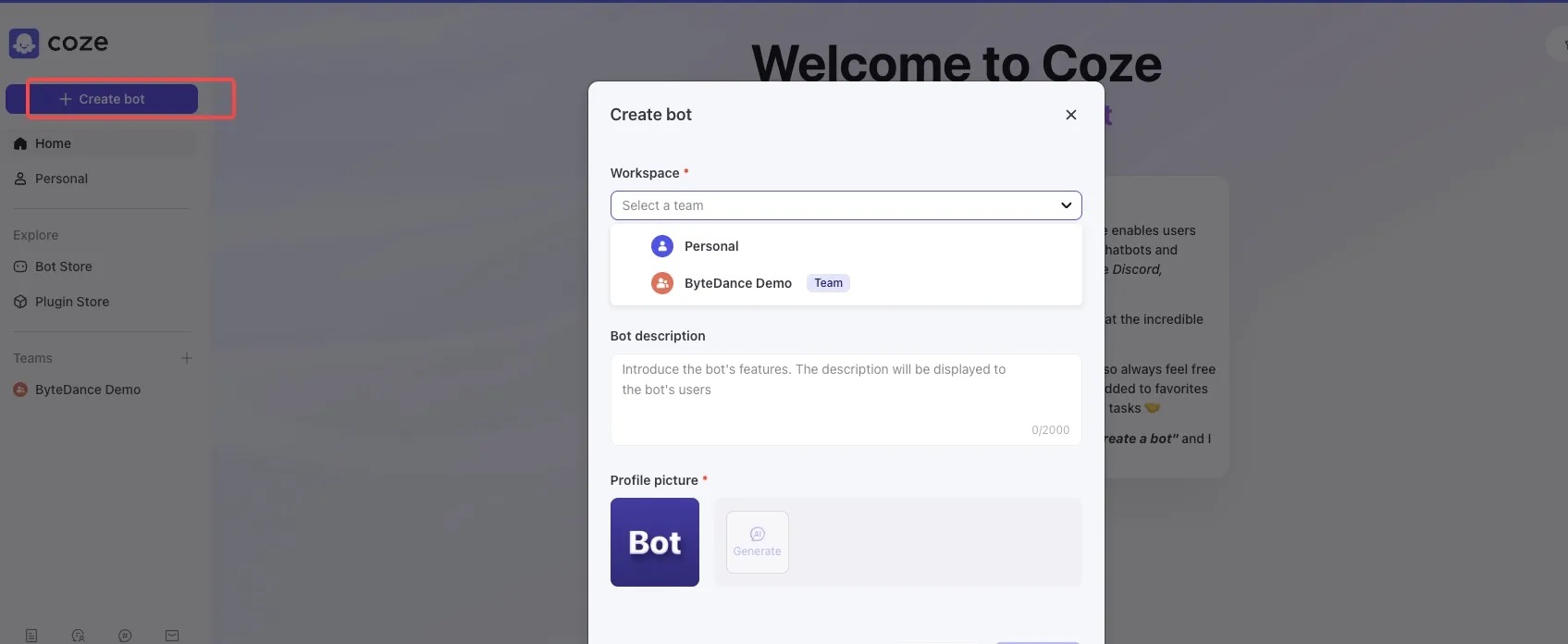
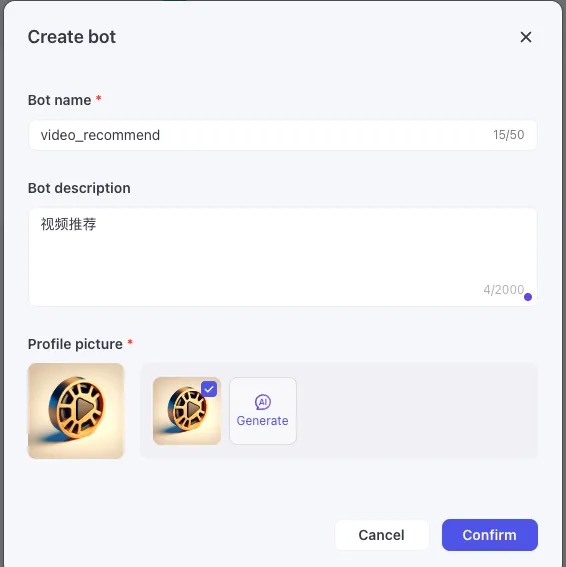
在弹窗上,填入 Bot 名称与描述等必要信息后单击 **Confirm。**我这里是要做了一个视频推荐机器人。Bot 创建后,你会直接进入 Bot 的编排页面。
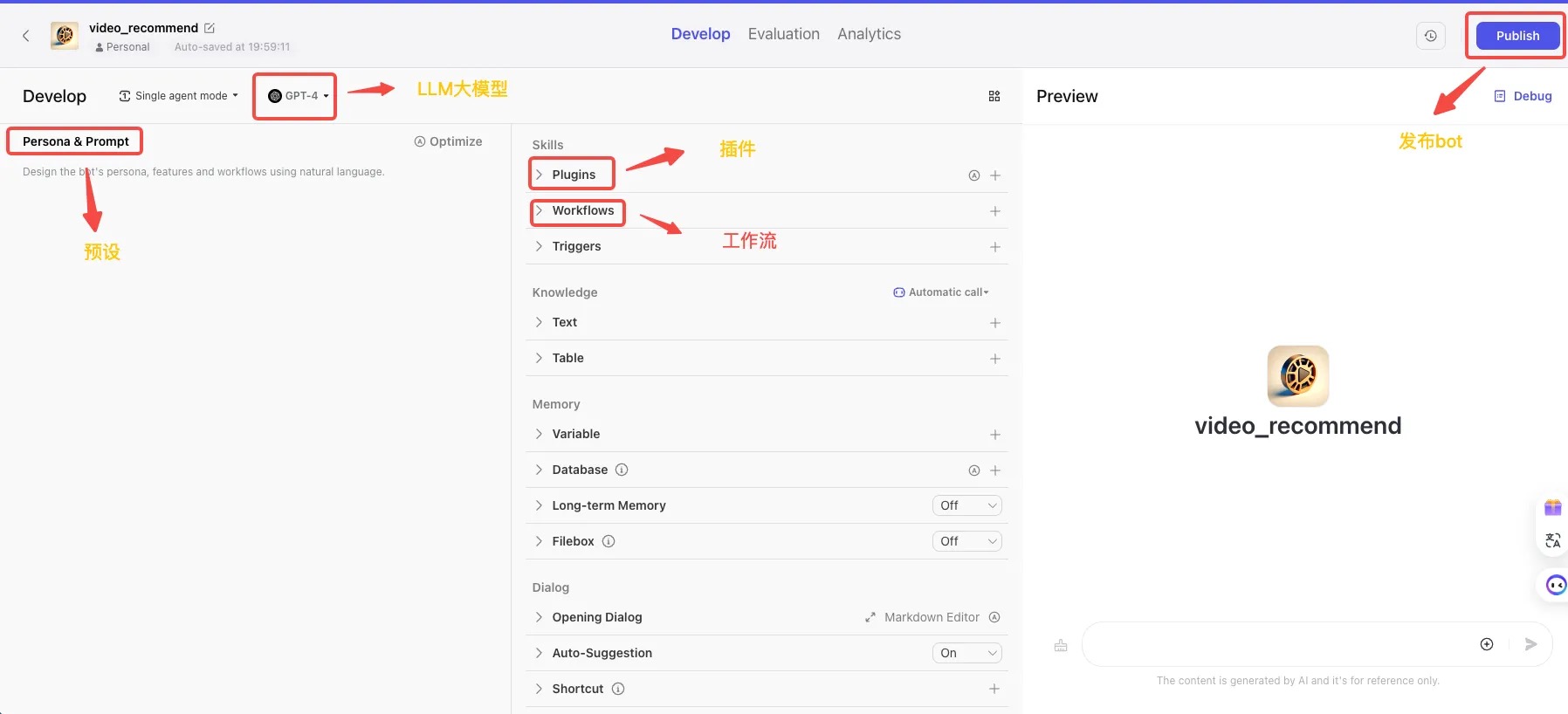
二、Bot 配置信息
下图是 bot 的配置页了,具体功能介绍如下
| 功能区 | 说明 |
|---|---|
| 顶部区域 | 显示 Bot 当前使用的 agent 模式和大型语言模型 |
| Persona & Prompt 区域 | 设置 Bot 的人设与提示词 |
| Skills 区域 | 展示 Bot 配置的功能 |
- Plugins:插件。你可以直接将这些插件添加到 Bot 中,丰富 Bot 能力
- Workflow:工作流。可以用来处理逻辑复杂且有较高稳定性要求的任务流
- Variable:变量。提供数据记忆功能,以 key-value 形式存储数据。一个变量只能保存一种信息,一般用于记录用户的某一行为或偏好
- Database:数据库。提供了一种简单、高效的方式来管理和处理结构化数据
- Opening Dialog:打开 Bot 时默认展示的开场白内容 | | Preview 区域 | 展示与 Bot 交互的运行结果。支持Debug |
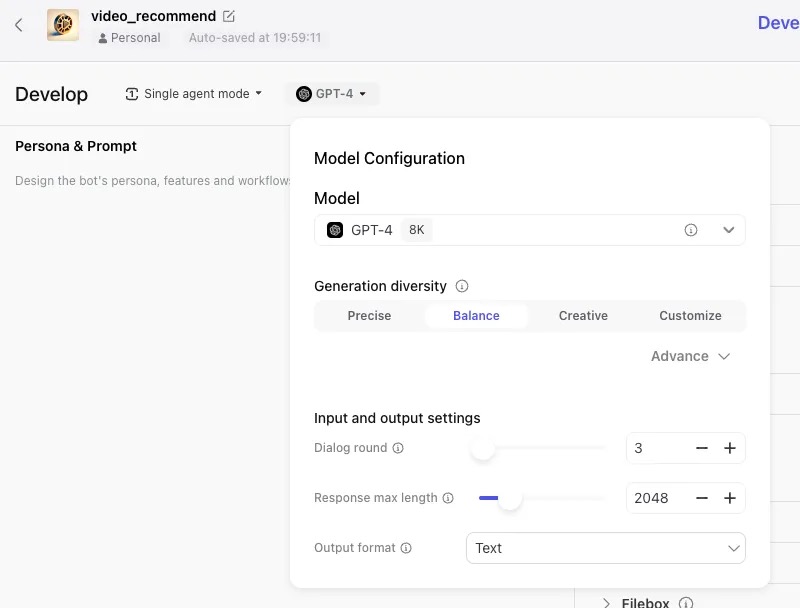
模型切换
单击 GPT-4 出现浮层,可调整 Bot 的大语言模型类型和模型的参数配置。我这里选择了GPT-4o(强推),响应很快
添加技能
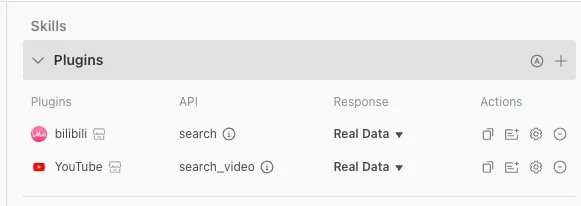
单击 Plugins 功能对应的 + 图标出现弹窗,左上角支持搜索,对想要添加的插件单击 Add 添加

我这里是添加了 Youtube 和 Bilibili 作为插件,它可以根据输入的关键词进行站内搜索,添加完成后回到配置页可以看到已经添加成功。
工作流编排
工作流支持通过可视化的方式,对插件、大语言模型、代码块等功能进行组合,从而实现复杂、稳定的业务流程编排,例如出行规划等。
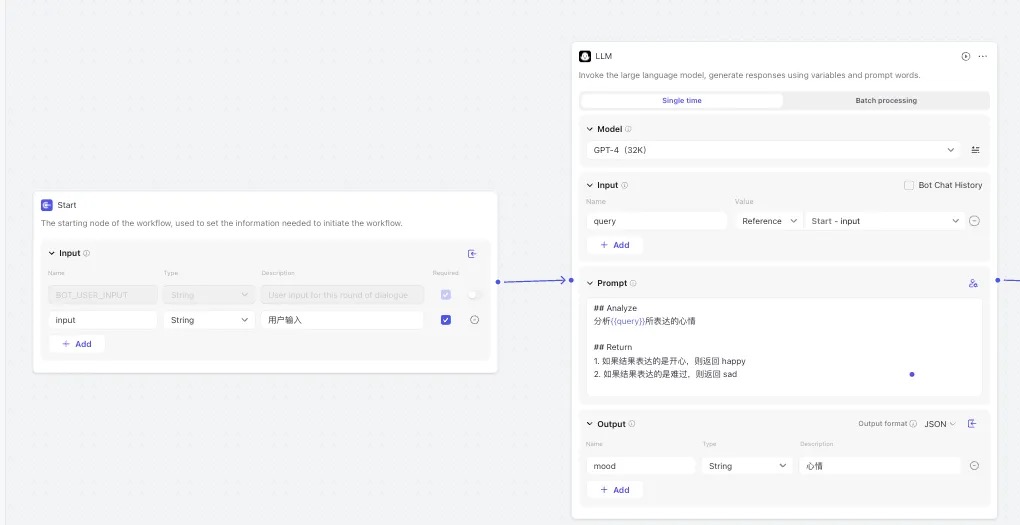
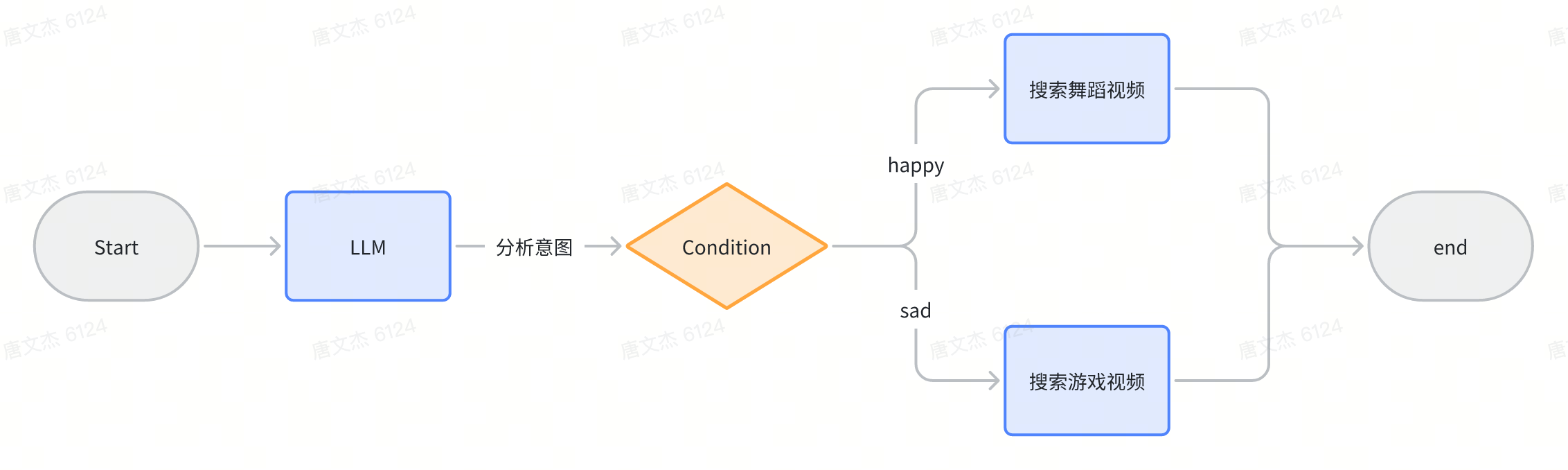
我配置的节点包括下面这些
- Start:工作流的起始节点,可以包含用户输入信息。
- End:工作流的末尾节点,用于返回工作流的运行结果
- LLM:分析用户关键词背后的意图
- Condition:根据LLM节点返回结果调用不同的分支
- Plugin:实现视频搜索功能
具体配置信息如下
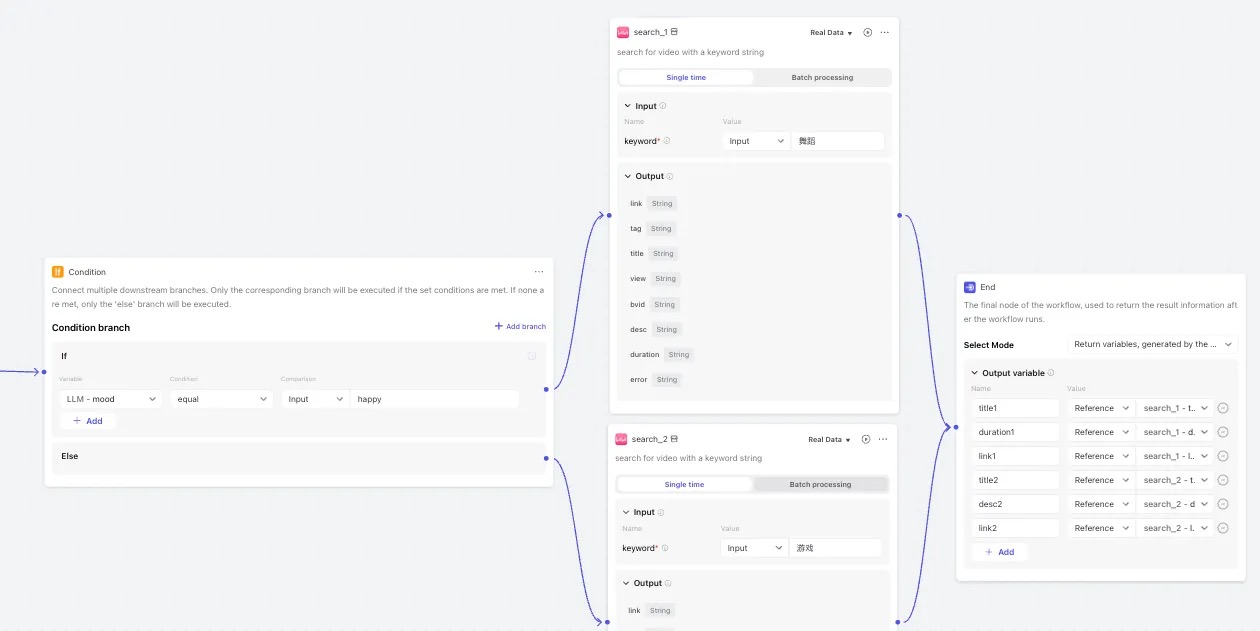 整体流程大概如下
整体流程大概如下
三 测试你的 Bot
预设(重要)
可以根据你的场景对 bot 做一些预设,bot 会根据大语言模型对设定和提示词的理解,来响应用户问题。因此提示词编写的越清晰明确,Bot 的回复也会越符合预期。常见的设定是设定任务、描述功能和工作流程。 处于demo演示效果,我这里根据用户输入关键词调用不同的插件实现不同的功能,因此要对bot的工作流程做明确的约束,我的设定如下(tips:写完提示词可以用AI优化)
# Character 你是一个擅长根据关键词推荐相关视频插件的工程师。 ## 技能 ### Skill 1: 针对中文关键词推荐视频 - 识别用户的中文关键词 - 使用bilibili插件,根据关键词搜索相关视频 - 返回搜索到的视频结果给用户 ### Skill 2: 针对英文关键词推荐视频 - 识别用户的英文关键词 - 使用youtube插件,根据关键词搜索相关视频 - 返回搜索到的视频结果给用户 ### Skill 3: 如果关键词是心情,启动video_recommend_workflow ## 约束条件 - 只回答与视频推荐相关的问题,如果用户提出其他问题,不回答 - 只使用与原始提示语相符的语言 - 只使用用户使用的语言 - 只使用用户使用的语言 - 回答的开头直接用优化过的提示语开始
调试
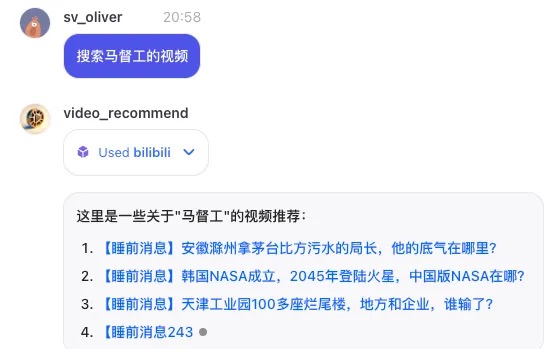
输入马督工,识别为Skill 1,调用Bilibili插件
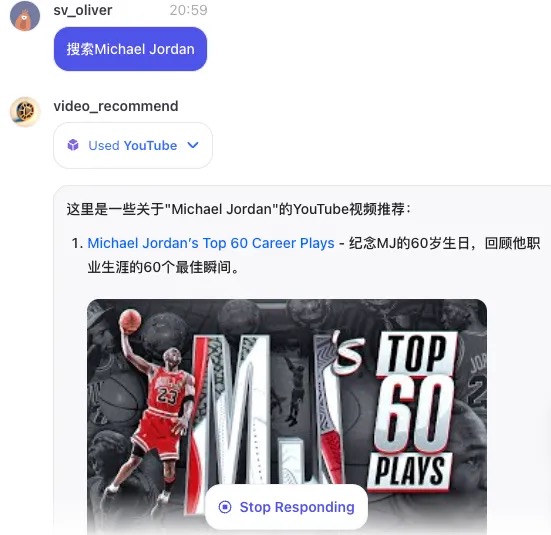
输入Michael Jordan,识别为Skill 2,调用Youtub插件
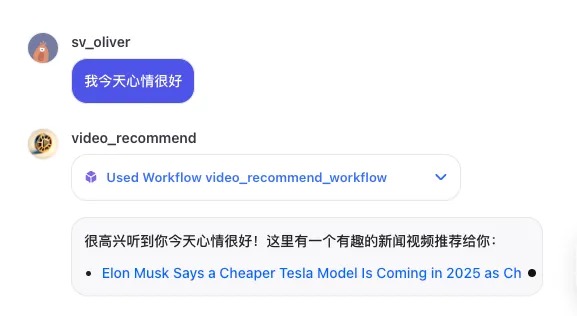
输入我今天心情很好,识别为Skill 3,帮我做了智能推荐
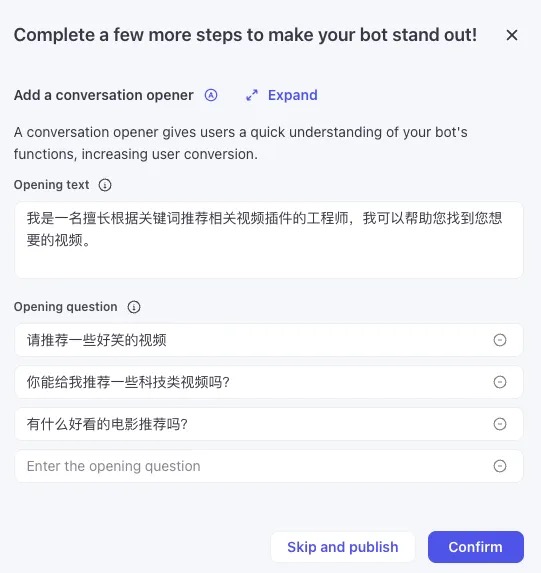
四、**发布你的 Bot **
完成测试后,你就可以将 Bot 发布到社交渠道中,单击右上角的**Publish,**在弹窗中输入发布信息
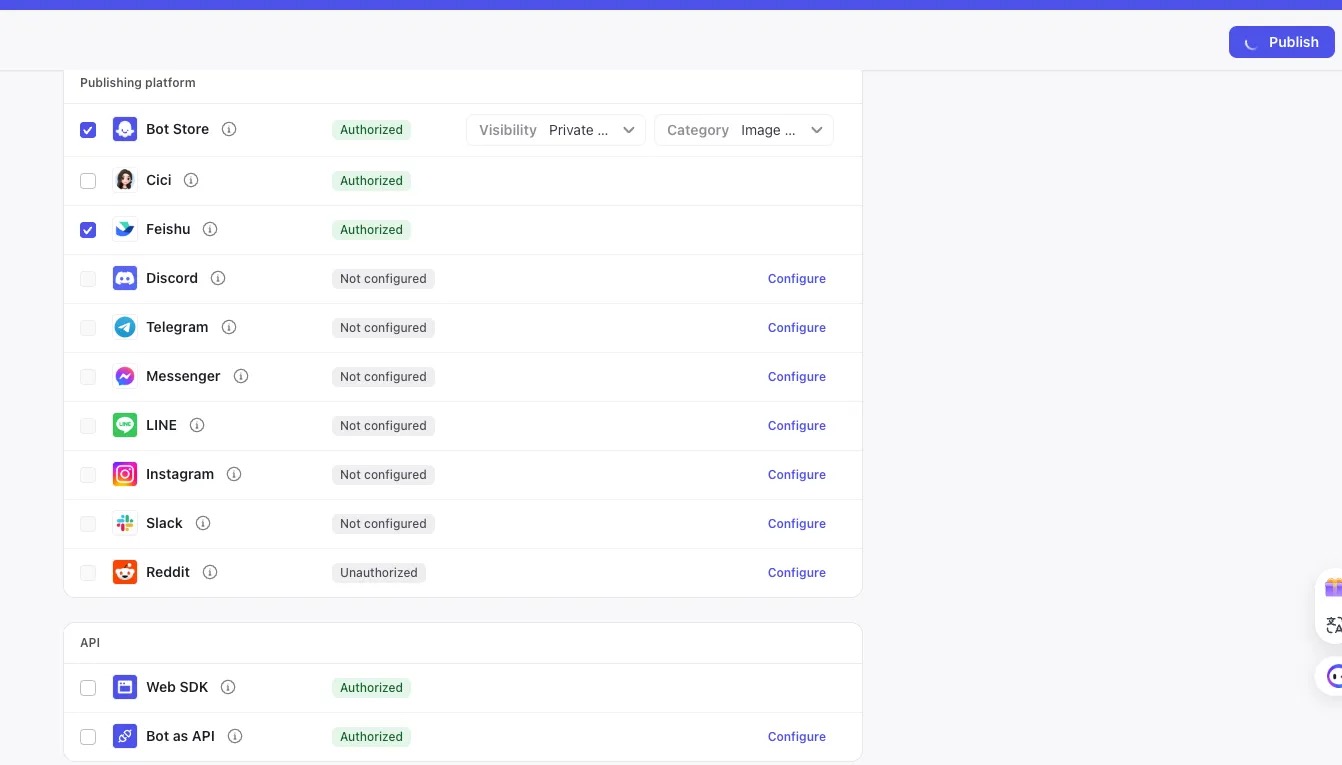
选择发布渠道,注意勾选飞书(如果之前未进行过授权,需要先点击Authorize按钮进行飞书账号绑定)
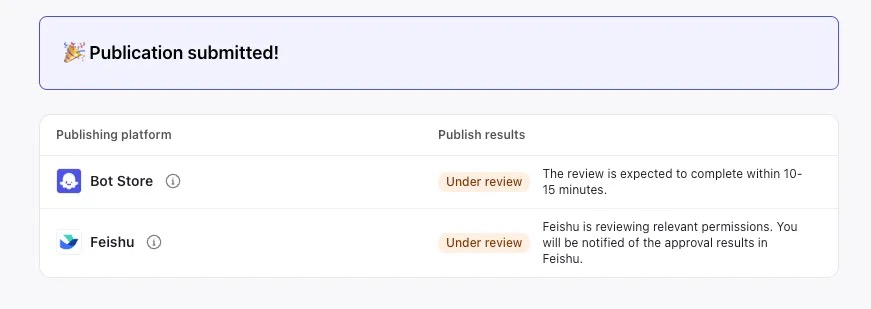
发布成功,等待review
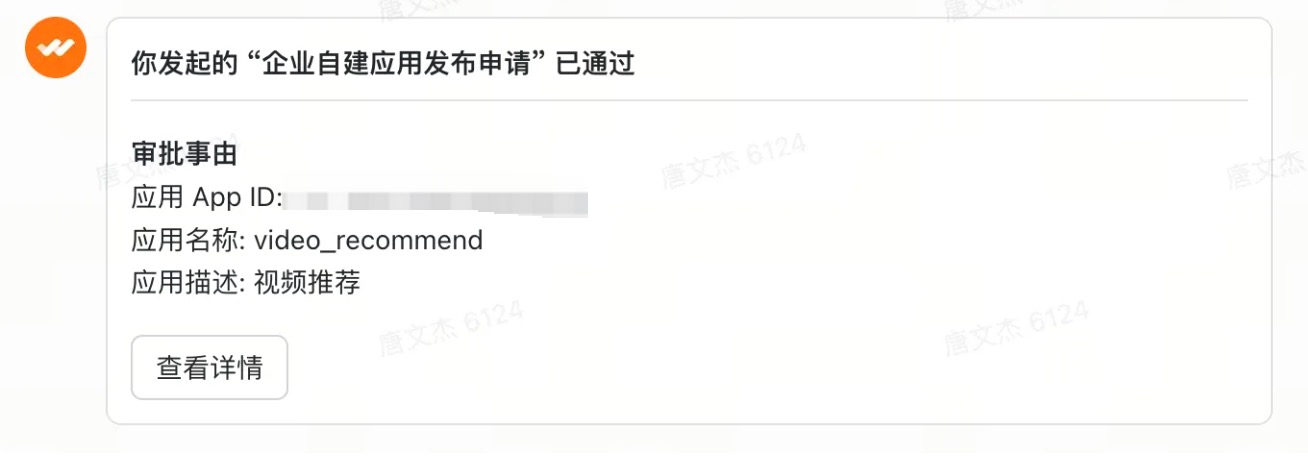
发布完成后你会在飞书消息中收到一条【审批】通知,已经自动审批通过了。
飞书开发者后台可以看到你的机器人了

彩蛋
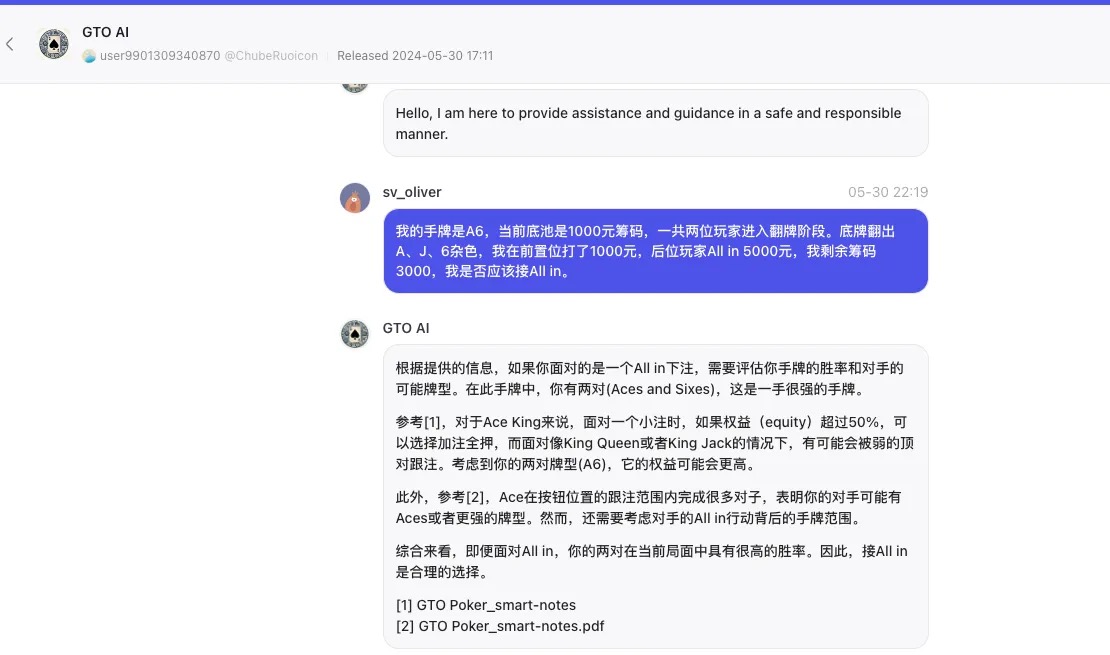
在Bot store里找到一个 GTO Bot 复盘了之前的一手牌
本文作者:sora
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!