目录
前言
在编程领域中,设计模式是针对特定问题的可重复解决方案。设计模式可以帮助程序员解决常见的设计问题,提高代码的可维护性、复用性和可扩展性。设计模式不是具体的代码,而是一种通用的解决方案模板,它提供了一套经过验证的方法,用于解决特定类型的问题。
设计模式的主要目的是提高软件的可维护性、通用性和扩展性,并且通过提供标准化的方法简化系统设计,同时也使代码更加优雅、清晰、易于理解和管理。
一、设计原则
开闭原则(OCP)
对扩展开放,对修改关闭。 这是整个设计模式中很大的一个基础原则,要求类的改动是通过增加代码来实现的,而不是修改源代码。 场景:通过一个买手机的场景,来贯穿整个设计原则的理解。
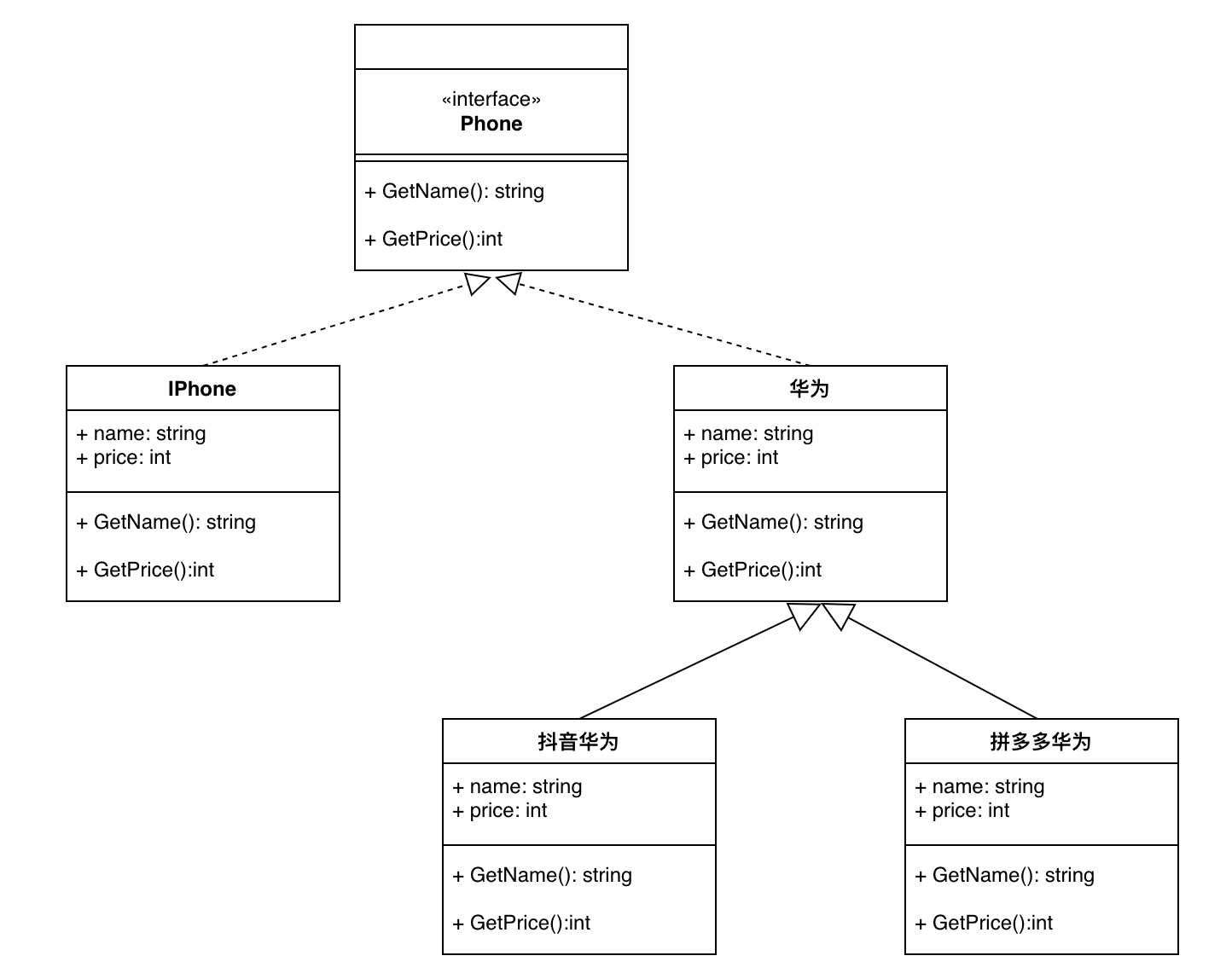
手机接口定义了两个方法,分别是获得手机型号和手机价格,IPhone和华为分别为两个实现类 Phone接口的代码清单如下:
type Phone interface { GetName() string GetPrice() int64 }
华为实现类的代码清单如下:
type HuaWei struct { name string price int64 } func (h *HuaWei) GetName() string { return h.name } func (h *HuaWei) GetPrice() int64 { return h.price }
单测清单如下:
func TestOCP(t *testing.T) { var phone Phone phone = &HuaWei{ name: "huawei", price: 2333, } fmt.Println(phone.GetPrice()) }
场景:马上618,华为手机参与抖音活动,满100返20,如何设计代码? 解决思路: 在这个问题中,我们先只考虑当前场景,不做其他扩展考虑,尽量把每一个需求原子化。
- 修改华为实现类,直接修改GetPrice方法,计算满减后的金额,好处是只需要修改华为实现类,但是会丢失华为手机本身的价格,也会影响华为手机在其他销售渠道的价格。
- 修改手机接口,新增一个参与活动方法,入参为活动力度,出参为通过活动力度算出来的价格。造成的影响是接口和华为手机实现类都需要修改,而接口应该是足够稳定的,不应该频繁修改,否则就失去了接口的契约性。
- 使用抖音华为手机这个子类来拓展,子类中覆写父类的GetPrice方法,以此来实现在抖音中满减购买华为手机的逻辑,不会影响其他业务。
type DouYinHuaWei struct { HuaWei } func (h *DouYinHuaWei) GetPrice() int64{ h.price = h.price - h.price/100*20 return h.price }
我们通过拓展子类的形式来面对多变的需求,而较少的去变动底层设计,开闭原则提倡的是尽可能通过拓展来实现变化,尽可能少的去改变现有的模块。
开闭原则总结:类的改动是通过增加代码来实现的,而不是修改源代码,提高代码复用性,可维护性。
单一职责原则(SRP)
类的职责单一,对外只提供一种功能,而引起类变化的原因都应该只有一个。保证设计类、接口、方法时做到功能单一,权责明确。
如果模块或类承担的职责过多,就等于这些职责耦合在一起, 这样一个模块的变化可能会削弱或抑制其它模块的能力, 这样的耦合是十分脆弱地。所以应该尽量保持单一职责原则, 此原则的核心就是解耦和增强内聚性。
在考虑单一职责原则的时候,最重要考虑的就是职责划分,从小往大说,分别需要考虑方法的划分,类的划分,层次的划分(比如将service层和dao层混在一起),服务的划分(微服务中领域的边界)。 还以上面卖手机的例子来说:
-
华为手机参加抖音活动,新建抖音华为子类A,如果参加拼多多百亿补贴可以建对应的子类B,A和B可以做独立的业务逻辑,同时又继承相同的父类,做到类上的高内聚低耦合;
-
假如我们需要修改手机的价格,就单个服务而言,在dao层提供一个关于手机类的通用update接口,在service层提供一个修改价格的接口,在service层做好限制条件和数据处理,然后送到dao层做CRUD的原子操作,同时即使数据库从mysql变成了oracle,只需要修改dao层的代码,复用service层的代码。
-
用户在购买手机的时候需要先登录,在服务体量较大的时候需要考虑将高频模块用户服务独立出来,单独为用户服务扩容,然后多实例负载均衡,因为在商品,下单,支付,履约中都需要用户登录态,如果这些服务放在一起会造成资源的浪费,并且牵一发而动全身,互相影响。 单一职责原则总结:降低类的复杂性,提高代码可读性、可维护性。
里氏替换原则(LSP)
任何抽象类(interface接口)出现的地方都可以用他的实现类进行替换。 里氏代换原则是对“开-闭”原则的补充,也是继承复用的基石。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。 很多时候会听到里氏替换原则就是多态,其实是一种不规范的说法,多态有三种表现形式,分别是:
-
特设多态,即同一操作,不同类型会有不同行为,典型的就是重载,最常用的地方就是构造器重载
-
参数化多态,操作与类型无关,典型的就是泛型,常见地方为当一个操作与参数类型无关,而希望对各种参数类型都适用的时候
-
子类型多态,同一对象可能属于多种类型,典型的就是继承、重写
里氏替换原则要求子类从抽象继承而不是具体继承,在概念中说到,里氏替换原则是对实现抽象化的具体步骤的规范,如果从抽象继承,子类必然要重写父类方法,这样看就很清晰,里氏替换原则属于第三种子类型多态,因此里氏替换原则和多态是相辅相成的。同样上面的例子也能很好的做出说明,用户现在需要打电话,只是需要一个手机,当前不在乎品牌,先给一个phone,等到关注具体品牌的时候再考虑是iphone还是华为。
依赖倒置原则(DIP)
面向接口编程,依赖于抽象的接口,不要依赖具体的实现
具体来讲,依赖倒置原则要求我们在程序代码中传递参数时或在依赖关系中,尽量引用抽象层,即使用接口或抽象类进行变量类型声明、参数类型声明、方法返回类型声明,以及数据类型的转换,而不要用具体的类来做这些事情。
来个示例,还以上面手机的场景,我们现在引入顾客的角色,顾客目前有学生和公务员,依赖关系如下图
这是一个耦合度极高的设计,实现代码如下
type IPhone struct{} func (p *IPhone) Call() { fmt.Println("iphone is calling...") } type HuaWei struct{} func (p *HuaWei) Call() { fmt.Println("huawei is calling...") } type Student struct{} func (c *Student) UseIPhone(p *IPhone) { fmt.Println("student is using iphone") p.Call() } func (c *Student) UseHuawei(p *HuaWei) { fmt.Println("student is using huawei") p.Call() } type Coder struct{} func (c *Coder) UseIPhone(p *IPhone) { fmt.Println("coder is using iphone") p.Call() } func (c *Coder) UseHuawei(p *HuaWei) { fmt.Println("coder is using huawei") p.Call() }
采用依赖倒置原则进行改造
实现代码如下
// 抽象层 type Phone interface { Call() } type Customer interface { Use(p Phone) } // 实现层 type IPhone struct{} func (p *IPhone) Call() { fmt.Println("iphone is calling...") } type HuaWei struct{} func (p *HuaWei) Call() { fmt.Println("huawei is calling...") } type Student struct{} func (c *Student) Use(p Phone) { fmt.Println("student is using phone") p.Call() } type Coder struct{} func (c *Coder) Use(p Phone) { fmt.Println("coder is using phone") p.Call() } // 业务逻辑层 func main() { // coder use huawei var coder Customer coder = &Coder{} var huawei Phone huawei = &HuaWei{} coder.Use(huawei) }
依赖倒置原则总结:高层模块不应该依赖底层模块,都应该依赖抽象的接口;接口不应该依赖于实现;实现应该依赖于抽象的接口。
接口隔离原则(ISP)
一个接口应该只提供一种对外功能,不应该把所有的操作都封装在一个接口中去。
接口隔离原则主要观点在于一个类对另外一个类的依赖性应当是建立在最小的接口上的;上游依赖方不应该依赖它不需要的接口功能。
接口隔离原则和单一职责原则在概念上是有一定的相似之处,这是很正常的现象,很多设计模式在概念上都有交叉,最终实现的是高内聚,低耦合的效果,接口隔离原则更加强调接口对上游依赖方的承诺越少越好,并且要做到专一,当需求发生改变从而迫使接口需要调整时,尽量使得调整少干扰其他接口,避免接口污染。
感受:招商oec.promotiion.campaign_center里的MGetSubCampaignExtraInfo,按需拿数据 总结下来,接口隔离原则要求接口尽量粒度化,保持接口纯洁性;接口要高内聚,减少对外交互。
迪米特法则(LOD)
也叫最少知道原则,一个软件实体应当尽可能少的与其他实体发生依赖关系,为了降低类之间的耦合 这里是不是发现单一职责原则、接口隔离原则、迪米特法则有种殊途同归的感觉。
依旧以买手机为例子,同学A想买一部IPhone,只需要打开抖音下单即可,他不需要关心这部手机现在在什么地方,由哪个仓发出,由哪位快递员送到自己手中,这就是个典型的迪米特法则的运用。 实现代码如下:
type Douyin struct{} func(d *Douyin) Order() (p Phone){ return p } type Customer struct{} func(c *Customer) Buy(d Douyin) (p Phone){ d.Order() }
合成复用原则(CARP)
通过将已有的对象作为成员对象纳入到新对象当中,新对象可以调用已有对象的功能,从而达到复用,原则上是尽量优先使用组合的方式,而不是继承。
如果使用继承,会导致父类的任何变换都可能影响到子类的行为。如果使用对象组合,就降低了这种依赖关系。对于继承和组合,优先使用组合。
在Go语言中继承是通过组合来实现的,二者的具体区别如下:
如果一个struct嵌套了另一个有名结构体,那么这个模式就叫组合。
type A struct{} func (a *A) do(){...} type B struct{ a A }
如果一个struct嵌套了另一个匿名结构体(只有类型没有名字),那么这个结构可以直接访问匿名结构体的方法,从而实现了继承。
type A struct{} func (a *A) do(){...} type B struct{ A }
二、设计模式
创建型模式
单例模式
单例模式的标准类图如下:

Singleton(单例):在单例类的内部实现只生成一个实例,同时它提供一个静态的getInstance()工厂方法,让客户可以访问它的唯一实例;为了防止在外部对其实例化,将其构造函数设计为私有;在单例类内部定义了一个Singleton类型的静态对象,作为外部共享的唯一实例。 单例模式要解决的问题是:保证一个类永远只能有一个实例对象,且该对象的功能依然能被其他模块使用 单例模式代码实现
package main import "fmt" /* 三个要点: 一是某个类只能有一个实例; 二是它必须自行创建这个实例; 三是它必须自行向整个系统提供这个实例。 */ /* 保证一个类永远只能有一个对象 */ //1、保证这个类非公有化,外界不能通过这个类直接创建一个对象 // 那么这个类就应该变得非公有访问 类名称首字母要小写 type singelton struct {} //2、但是还要有一个指针可以指向这个唯一对象,但是这个指针永远不能改变方向 // Golang中没有常指针概念,所以只能通过将这个指针私有化不让外部模块访问 var instance *singelton = new(singelton) //3、如果全部为私有化,那么外部模块将永远无法访问到这个类和对象, // 所以需要对外提供一个方法来获取这个唯一实例对象 // 注意:这个方法是否可以定义为singelton的一个成员方法呢? // 答案是不能,因为如果为成员方法就必须要先访问对象、再访问函数 // 但是类和对象目前都已经私有化,外界无法访问,所以这个方法一定是一个全局普通函数 func GetInstance() *singelton { return instance } func (s *singelton) SomeThing() { fmt.Println("单例对象的某方法") } func main() { s := GetInstance() s.SomeThing() }
上面代码推演了一个单例的创建过程,上述是单例模式中的一种,属于“饿汉式”。含义是,在初始化单例唯一指针的时候,就已经提前开辟好了一个对象,申请了内存。饿汉式的好处是,不会出现线程并发创建,导致多个单例的出现,但是缺点是如果这个单例对象在业务逻辑没有被使用,也会客观的创建一块内存对象。那么与之对应的模式叫“懒汉式”,代码如下:
package main import "fmt" type singleton struct {} var instance *singleton func GetInstance() *singleton { //只有首次GetInstance()方法被调用,才会生成这个单例的实例 if instance == nil { instance = new(singleton) return instance } //接下来的GetInstance直接返回已经申请的实例即可 return instance } func (s *singleton) SomeThing() { fmt.Println("单例对象的某方法") } func main() { s := GetInstance() s.SomeThing() }
上面的“懒汉式”实现是非线程安全的设计方式,也就是如果多个线程或者协程同时首次调用GetInstance()方法有概率导致多个实例被创建,则违背了单例的设计初衷。那么在上面的基础上进行修改,可以利用Sync.Mutex进行加锁,保证线程安全。这种线程安全的写法,有个最大的缺点就是每次调用该方法时都需要进行锁操作,在性能上相对不高效,具体的实现改进如下:
package main import ( "fmt" "sync" ) //定义锁 var lock sync.Mutex type singleton struct {} var instance *singleton func GetInstance() *singleton { //为了线程安全,增加互斥 lock.Lock() defer lock.Unlock() if instance == nil { return new(singleton) } else { return instance } } func (s *singleton) SomeThing() { fmt.Println("单例对象的某方法") } func main() { s := GetInstance() s.SomeThing() }
上面代码虽然解决了线程安全,但是每次调用GetInstance()都要加锁会极大影响性能。所以接下来可以借助"sync/atomic"来进行内存的状态存留来做互斥。atomic就可以自动加载和设置标记,代码如下:
package main import ( "fmt" "sync" "sync/atomic" ) //标记 var initialized uint32 var lock sync.Mutex type singleton struct {} var instance *singleton func GetInstance() *singleton { //如果标记为被设置,直接返回,不加锁 if atomic.LoadUint32(&initialized) == 1 { return instance } //如果没有,则加锁申请 lock.Lock() defer lock.Unlock() if initialized == 0 { instance = new(singleton) //设置标记位 atomic.StoreUint32(&initialized, 1) } return instance } func (s *singleton) SomeThing() { fmt.Println("单例对象的某方法") } func main() { s := GetInstance() s.SomeThing() }
上述的实现其实Golang有个方法已经帮助开发者实现完成,就是Once模块,来看下Once.Do()方法的源代码:
func (o *Once) Do(f func()) { //判断是否执行过该方法,如果执行过则不执行 if atomic.LoadUint32(&o.done) == 1 { return } // Slow-path. o.m.Lock() defer o.m.Unlock() if o.done == 0 { defer atomic.StoreUint32(&o.done, 1) f() } }
所以完全可以借助Once来实现单例模式的实现,优化的代码如下:
package main import ( "fmt" "sync" ) var once sync.Once type singleton struct {} var instance *singleton func GetInstance() *singleton { once.Do(func(){ instance = new(singleton) }) return instance } func (s *singleton) SomeThing() { fmt.Println("单例对象的某方法") } func main() { s := GetInstance() s.SomeThing() }
单例模式优缺点:
优点
-
单例模式提供了对唯一实例的受控访问。
-
节约系统资源,由于在系统内存中只存在一个对象。
缺点
-
扩展略难,单例模式中没有抽象层。
-
单例类的职责过重。
适用场景:
-
系统只需要一个实例对象,如系统要求提供一个唯一的序列号生成器或资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象。
-
客户调用类的单个实例只允许使用一个公共访问点,除了该公共访问点,不能通过其他途径访问该实例。
团队中的使用场景:跨层调用时获取下层对象
工厂方法模式
- 抽象工厂(Abstract Factory)角色:工厂方法模式的核心,任何工厂类都必须实现这个接口。
- 工厂(Concrete Factory)角色:具体工厂类是抽象工厂的一个实现,负责实例化产品对象。
- 抽象产品(Abstract Product)角色:工厂方法模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
- 具体产品(Concrete Product)角色:工厂方法模式所创建的具体实例对象。 工厂方法模式 = 简单工厂模式 + “开闭原则” 工厂方法模式的标准类图如下
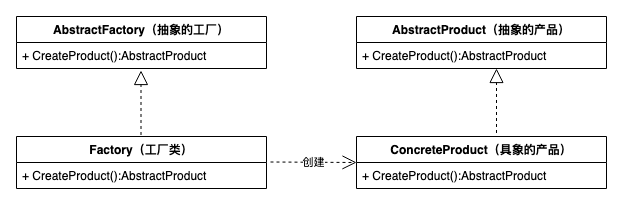
工厂方法模式代码实现如下
package main import "fmt" // ======= 抽象层 ========= // 手机类(抽象接口) type Phone interface { Call() //接口的某方法 } // 工厂类(抽象接口) type AbstractFactory interface { CreatePhone() Phone //生产手机类(抽象)的生产器方法 } // ======= 基础类模块 ========= type IPhone struct { Phone //为了易于理解显示继承(此行可以省略) } func (iphone *IPhone) Call() { fmt.Println("use IPhone") } type HuaWei struct { Phone } func (huaWei *HuaWei) Call() { fmt.Println("use HuaWei") } type XiaoMi struct { Phone } func (xiaoMi *XiaoMi) Call() { fmt.Println("use XiaoMi") } // ========= 工厂模块 ========= // 具体的iphone工厂 type IPhoneFactory struct { AbstractFactory } func (fac *IPhoneFactory) CreatePhone() Phone { var phone Phone //生产一个具体的Iphone phone = new(IPhone) return phone } // 具体的huawei工厂 type HuaWeiFactory struct { AbstractFactory } func (fac *HuaWeiFactory) CreatePhone() Phone { var phone Phone //生产一个具体的huawei phone = new(HuaWei) return phone } // 具体的xiaomi工厂 type XiaoMiFactory struct { AbstractFactory } func (fac *XiaoMiFactory) CreatePhone() Phone { var phone Phone //生产一个具体的手机 phone = new(XiaoMi) return phone } // ======= 业务逻辑层 ======= func main() { /* 本案例为了突出根据依赖倒转原则与面向接口编程特性。 一些变量的定义将使用显示类型声明方式 */ //需求:需要一个具体的手机对象 //1-先要一个具体的iphone工厂 var iphoneFac AbstractFactory iphoneFac = new(IPhoneFactory) //2-生产相对应的具体手机 var iphone Phone iphone = iphoneFac.CreatePhone() iphone.Call() }
优点:
-
不需要记住具体类名,甚至连具体参数都不用记,需要创建调工厂方法即可
-
实现了对象创建和使用的分离
-
系统的可扩展性也就变得非常好,无需修改接口和原类
-
对于新对象的创建,符合开闭原则,和简单工厂方法做比较
缺点:
-
增加系统中类的个数,复杂度和理解度增加
-
增加了系统的抽象性和理解难度
适用场景:
-
客户端不知道它所需要的对象的类
-
抽象工厂类通过其子类来指定创建哪个对象
抽象工厂方法模式
工厂方法模式通过引入工厂等级结构,解决了简单工厂模式中工厂类职责太重的问题,但由于工厂方法模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。因此,可以考虑将一些相关的产品组成一个“产品族”,由同一个工厂来统一生产,这就是抽象工厂模式的基本思想。
- 抽象工厂(Abstract Factory)角色:它声明了一组用于创建一族产品的方法,每一个方法对应一种产品。
- 具体工厂(Concrete Factory)角色:它实现了在抽象工厂中声明的创建产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中。
- 抽象产品(Abstract Product)角色:它为每种产品声明接口,在抽象产品中声明了产品所具有的业务方法。
- 具体产品(Concrete Product)角色:它定义具体工厂生产的具体产品对象,实现抽象产品接口中声明的业务方法。
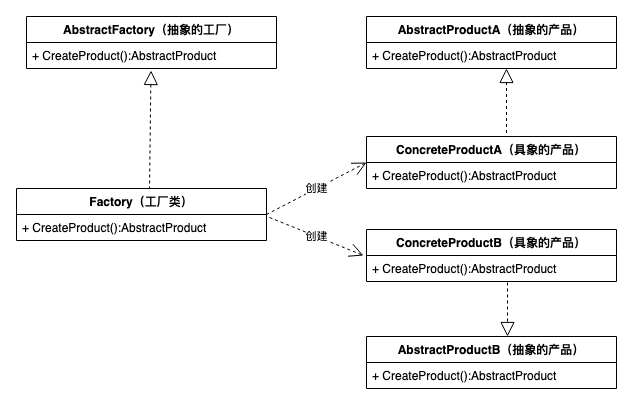
手机工厂类可以一起创建手机和手机壳、手机膜 代码实现如下:
package main import "fmt" // ======= 抽象层 ========= type AbstractPhone interface { Call() } type AbstractDecorator interface { Decorate() } // 抽象工厂 type AbstractFactory interface { CreatePhone() AbstractPhone CreateDecorator() AbstractDecorator } // ======== 实现层 ========= /* iphone产品族 */ type IPhone struct{} func (i *IPhone) Call() { fmt.Println("use iphone") } type IPhoneDecorator struct{} func (i *IPhoneDecorator) Decorate() { fmt.Println("decorate on iphone") } type IPhoneFactory struct{} func (i *IPhoneFactory) CreatePhone() AbstractPhone { var phone AbstractPhone phone = new(IPhone) return phone } func (i *IPhoneFactory) CreateDecorator() AbstractDecorator { var decorator AbstractDecorator decorator = new(IPhoneDecorator) return decorator } // ======== 业务逻辑层 ======= func main() { //需求1: 需要iphone的手机和装饰品等对象 //1-创建一个iphone工厂 var aFac AbstractFactory aFac = new(IPhoneFactory) //2-生产iphone var phone AbstractPhone phone = aFac.CreatePhone() phone.Call() //3-生产装饰器 var decorator AbstractDecorator decorator = aFac.CreateDecorator() decorator.Decorate() }
优点:
-
拥有工厂方法模式的优点
-
当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象
-
增加新的产品族很方便,无须修改已有系统,符合“开闭原则”
缺点:增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了“开闭原则”
适用场景:
-
系统中有多于一个的产品族。而每次只使用其中某一产品族。可以通过配置文件等方式来使得用户可以动态改变产品族,也可以很方便地增加新的产品族
-
产品等级结构稳定。设计完成之后,不会向系统中增加新的产品等级结构或者删除已有的产品等级结构
结构型模式
适配器模式
将一个类的接口转换成用户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。标准类图如下

- Target(目标抽象类):目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。
- Adapter(适配器类):适配器可以调用另一个接口,作为一个转换器,对Adaptee和Target进行适配,适配器类是适配器模式的核心,在对象适配器中,它通过继承Target并关联一个Adaptee对象使二者产生联系。 Adaptee(适配者类):适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法,在某些情况下可能没有适配者类的源代码。 根据对象适配器模式结构图,在对象适配器中,客户端需要调用request()方法,而适配者类Adaptee没有该方法,但是它所提供的specificRequest()方法却是客户端所需要的。为了使客户端能够使用适配者类,需要提供一个包装类Adapter,即适配器类。这个包装类包装了一个适配者的实例,从而将客户端与适配者衔接起来,在适配器的request()方法中调用适配者的specificRequest()方法。因为适配器类与适配者类是关联关系(也可称之为委派关系),所以这种适配器模式称为对象适配器模式。 (适配器模式一般分为三类:类适配器模式、对象适配器模式、接口适配器模式)
- 类适配器模式,继承源类,实现目标接口。
- 对象适配器模式,持有源类的对象,把继承关系改变为组合关系。
- 接口适配器模式,借助中间抽象类空实现目标接口所有方法,适配器选择性重写。
以手机充电为例,需要通过手机充电器将220v的电压转化为5v的电压来给手机充电
package main import "fmt" //适配的目标 type V5 interface { Use5V() } //业务类,依赖V5接口 type Phone struct { v V5 } func NewPhone(v V5) *Phone { return &Phone{v} } func (p *Phone) Charge() { fmt.Println("Phone进行充电...") p.v.Use5V() } //被适配的角色,适配者 type V220 struct {} func (v *V220) Use220V() { fmt.Println("使用220V的电压") } //电源适配器 type Adapter struct { v220 *V220 } func (a *Adapter) Use5V() { fmt.Println("使用适配器进行充电") //调用适配者的方法 a.v220.Use220V() } func NewAdapter(v220 *V220) *Adapter { return &Adapter{v220} } // ------- 业务逻辑层 ------- func main() { iphone := NewPhone(NewAdapter(new(V220))) iphone.Charge() }
优点:
-
将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无须修改原有结构。
-
增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用。
-
灵活性和扩展性都非常好,可以很方便地更换适配器,也可以在不修改原有代码的基础上增加新的适配器类,完全符合“开闭原则”。
缺点:
- 适配器中置换适配者类的某些方法比较麻烦。
适用场景:
-
系统需要使用一些现有的类,而这些类的接口(如方法名)不符合系统的需要,甚至没有这些类的源代码。
-
想创建一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作。
调度中心的执行层
代理模式
Proxy模式又叫做代理模式,是结构型的设计模式之一,它可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问。
所谓代理,是指具有与代理元(被代理的对象)具有相同的接口的类,客户端必须通过代理与被代理的目标类交互,而代理一般在交互的过程中(交互前后),进行某些特别的处理。
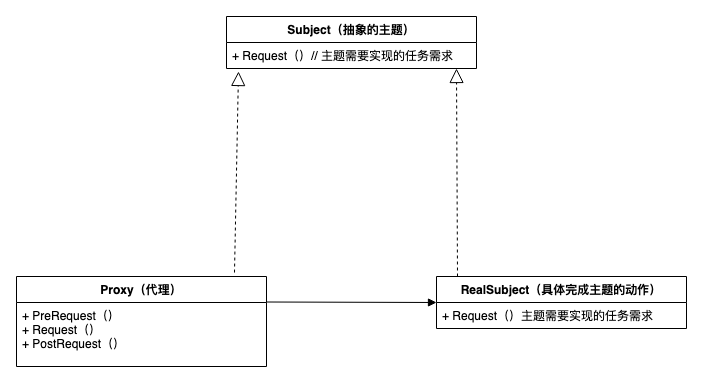
- subject(抽象主题角色):真实主题与代理主题的共同接口。
- RealSubject(真实主题角色):定义了代理角色所代表的真实对象。
- Proxy(代理主题角色):含有对真实主题角色的引用,代理角色通常在将客户端调用传递给真是主题对象之前或者之后执行某些操作,而不是单纯返回真实的对象。
以结婚为例
package main import "fmt" type Couple struct { Man string Woman string } // =========== 抽象层 =========== // 抽象的婚礼主题Subject type MarryHappy interface { Marry(couple *Couple) //某任务 } // =========== 实现层 =========== type XiaoMingMarryHappy struct{} func (xm *XiaoMingMarryHappy) Marry(couple *Couple) { fmt.Println(couple.Man, "marry with", couple.Woman) } // 婚庆代理 type MarryProxy struct { marry MarryHappy //代理某个主题,这里是抽象类型 } func (mp *MarryProxy) Marry(couple *Couple) { // 布置场地 fmt.Println("proxy decorate the hotel") // 真正要做的事情,结婚本身 fmt.Println(couple.Man, "marry with", couple.Woman) // 打扫场地 fmt.Println("proxy swap the hotel") } // 创建一个代理,并且配置关联被代理的主题 func NewProxy(marry MarryHappy) *MarryProxy { return &MarryProxy{marry} } func main() { c1 := Couple{ Man: "fwq", Woman: "dw", } var marry MarryHappy proxy := NewProxy(marry) proxy.Marry(&c1) }
上述演示的是静态代理,可以通过反射实现动态代理
Java中实现动态代理方式:
- JDK的动态代理:实现一个处理方法调用的Handler,用于实现代理方法的内部逻辑,实现InvocationHandler接口
- CGLib动态代理技术不需要目标对象实现自一个接口,只需要实现一个处理代理逻辑的切入类,并实现MethodInterceptor接口
Go中实现动态代理:
比较常用的是pig和monkey这两个代表,他们大概的方式简单归纳为都是类似于通过对编译后的汇编语言进行一定的侵入,也就是在二进制文件级别进行打桩的操作,可以理解为动态hook,常用场景为测试打桩
使用反射来进行
package main import ( "fmt" "reflect" ) type Hello struct { SayHello func() string } func main() { var hello Hello getType := reflect.TypeOf(hello) method := getType.Method(0) fmt.Println(method.Func) method.Func.Call([]reflect.Value{reflect.ValueOf(hello)}) }
golang里如何实现动态代理类:https://zhuanlan.zhihu.com/p/497730824
优点:
-
能够协调调用者和被调用者,在一定程度上降低了系统的耦合度。
-
客户端可以针对抽象主题角色进行编程,增加和更换代理类无须修改源代码,符合开闭原则,系统具有较好的灵活性和可扩展性。
缺点:
- 代理实现较为复杂。
适用场景:
- 为其他对象提供一种代理以控制对这个对象的访问。 任务执行中心
装饰器模式
动态地给一个对象增加一些额外的职责,就增加对象功能来说,装饰模式比生成子类实现更为灵活。装饰模式是一种对象结构型模式。 标准类图如下
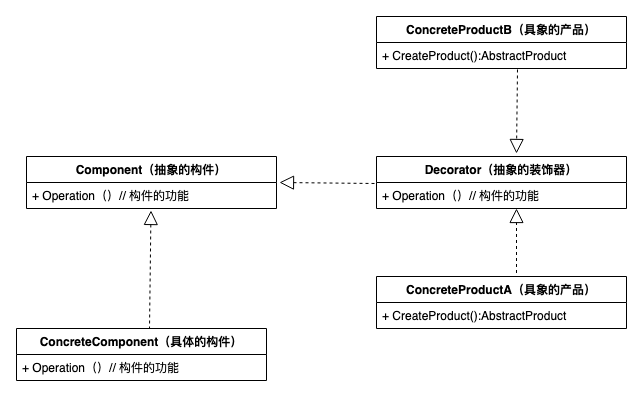
- Component(抽象构件):它是具体构件和抽象装饰类的共同父类,声明了在具体构件中实现的业务方法,它的引入可以使客户端以一致的方式处理未被装饰的对象以及装饰之后的对象,实现客户端的透明操作。
- ConcreteComponent(具体构件):它是抽象构件类的子类,用于定义具体的构件对象,实现了在抽象构件中声明的方法,装饰器可以给它增加额外的职责(方法)。
还是以抽象工厂方法模式中的手机、手机壳、手机膜为例
package main import "fmt" // ---------- 抽象层 ---------- //抽象的构件 type Phone interface { Show() //构件的功能 } //装饰器基础类(该类本应该为interface,但是Golang interface语法不可以有成员属性) type Decorator struct { phone Phone } func (d *Decorator) Show() {} // ----------- 实现层 ----------- // 具体的构件 type HuaWei struct {} func (hw *HuaWei) Show() { fmt.Println("HuaWei手机") } type XiaoMi struct{} func (xm *XiaoMi) Show() { fmt.Println("XiaoMi手机") } // 具体的装饰器类 type MoDecorator struct { Decorator //继承基础装饰器类(主要继承Phone成员属性) } func (md *MoDecorator) Show() { md.phone.Show() //调用被装饰构件的原方法 fmt.Println("贴膜的手机") //装饰额外的方法 } func NewMoDecorator(phone Phone) Phone { return &MoDecorator{Decorator{phone}} } type KeDecorator struct { Decorator //继承基础装饰器类(主要继承Phone成员属性) } func (kd *KeDecorator) Show() { kd.phone.Show() fmt.Println("手机壳的手机") //装饰额外的方法 } func NewKeDecorator(phone Phone) Phone { return &KeDecorator{Decorator{phone}} } // ------------ 业务逻辑层 --------- func main() { var huawei Phone huawei = new(HuaWei) huawei.Show() //调用原构件方法 fmt.Println("---------") //用贴膜装饰器装饰,得到新功能构件 var moHuawei Phone moHuawei = NewMoDecorator(huawei) //通过HueWei ---> MoHuaWei moHuawei.Show() //调用装饰后新构件的方法 fmt.Println("---------") var keHuawei Phone keHuawei = NewKeDecorator(huawei) //通过HueWei ---> KeHuaWei keHuawei.Show() fmt.Println("---------") var keMoHuaWei Phone keMoHuaWei = NewMoDecorator(keHuawei) //通过KeHuaWei ---> KeMoHuaWei keMoHuaWei.Show() } HuaWei手机 --------- HuaWei手机 贴膜的手机 --------- HuaWei手机 手机壳的手机 --------- HuaWei手机 手机壳的手机 贴膜的手机
优点:
-
对于扩展一个对象的功能,装饰模式比继承更加灵活性,不会导致类的个数急剧增加。
-
可以通过一种动态的方式来扩展一个对象的功能,从而实现不同的行为。
-
可以对一个对象进行多次装饰。
-
具体构件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体构件类和具体装饰类,原有类库代码无须改变,符合“开闭原则”。
缺点:
-
使用装饰模式进行系统设计时将产生很多小对象,大量小对象的产生势必会占用更多的系统资源,影响程序的性能。
-
装饰模式提供了一种比继承更加灵活机动的解决方案,但同时也意味着比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为繁琐。
适用场景:
-
动态、透明的方式给单个对象添加职责。
-
当不能采用继承的方式对系统进行扩展或者采用继承不利于系统扩展和维护时可以使用装饰模式。
装饰器和代理之间的区别?
装饰器模式关注于在一个对象上动态的添加方法,然而代理模式关注于控制对对象的访问。换句话说,用代理模式,代理类(proxy class)可以对它的客户隐藏一个对象的具体信息。因此,当使用代理模式的时候,我们常常在一个代理类中创建一个对象的实例。并且,当我们使用装饰器模式的时候,我们通常的做法是将原始对象作为一个参数传给装饰者的构造器。
外观模式
根据迪米特法则,如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。 Facade模式也叫外观模式,是由GoF提出的23种设计模式中的一种。Facade模式为一组具有类似功能的类群,比如类库,子系统等等,提供一个一致的简单的界面。这个一致的简单的界面被称作facade。
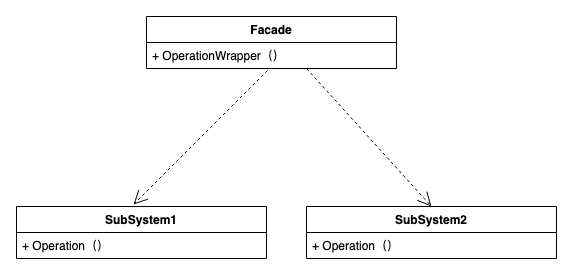
- Facade(外观角色):为调用方, 定义简单的调用接口。
- SubSystem(子系统角色):功能提供者。指提供功能的类群(模块或子系统)。
以手机打开智能观影系统为例
package main import "fmt" type SubSystemPlay struct{} func (sa *SubSystemPlay) MethodPlay() { fmt.Println("游戏子系统") } type SubSystemWatch struct{} func (sb *SubSystemWatch) MethodWatch() { fmt.Println("观影子系统") } type SubSystemSmartHome struct{} func (sc *SubSystemSmartHome) MethodSmartHome() { fmt.Println("智能家居系统") } // 外观模式,提供了一个外观类, 简化成一个简单的接口供使用 type Facade struct { a *SubSystemPlay b *SubSystemWatch c *SubSystemSmartHome } func (f *Facade) WatchMode() { f.b.MethodWatch() f.c.MethodSmartHome() } func main() { //如果不用外观模式实现MethodWatch() 和 MethodSmartHome() sa := new(SubSystemWatch) sa.MethodWatch() sc := new(SubSystemSmartHome) sc.MethodSmartHome() fmt.Println("-----------") //使用外观模式 phone := Facade{ a: new(SubSystemPlay), b: new(SubSystemWatch), c: new(SubSystemSmartHome), } //调用外观包裹方法 phone.WatchMode() }
优点:
-
它对客户端屏蔽了子系统组件,减少了客户端所需处理的对象数目,并使得子系统使用起来更加容易。通过引入外观模式,客户端代码将变得很简单,与之关联的对象也很少。
-
它实现了子系统与客户端之间的松耦合关系,这使得子系统的变化不会影响到调用它的客户端,只需要调整外观类即可。
-
一个子系统的修改对其他子系统没有任何影响。
缺点:
-
不能很好地限制客户端直接使用子系统类,如果对客户端访问子系统类做太多的限制则减少了可变性和灵活性。
-
如果设计不当,增加新的子系统可能需要修改外观类的源代码,违背了开闭原则。
适用场景:
-
复杂系统需要简单入口使用。
-
客户端程序与多个子系统之间存在很大的依赖性。
-
在层次化结构中,可以使用外观模式定义系统中每一层的入口,层与层之间不直接产生联系,而通过外观类建立联系,降低层之间的耦合度。
行为型模式
模板方法模式
定义一个操作中算法的框架,而将一些步骤实现延迟到子类中。模板方法模式使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。模板方法模式是一种基于继承的代码复用技术,它是一种类行为型模式。 标准类图如下:

- AbstractClass(抽象类):在抽象类中定义了一系列基本操作(PrimitiveOperations),这些基本操作可以是具体的,也可以是抽象的,每一个基本操作对应算法的一个步骤,在其子类中可以重定义或实现这些步骤。同时,在抽象类中实现了一个模板方法(Template Method),用于定义一个算法的框架,模板方法不仅可以调用在抽象类中实现的基本方法,也可以调用在抽象类的子类中实现的基本方法,还可以调用其他对象中的方法。
- ConcreteClass(具体子类):它是抽象类的子类,用于实现在父类中声明的抽象基本操作以完成子类特定算法的步骤,也可以覆盖在父类中已经实现的具体基本操作。
一个模板方法是定义在抽象类中的、把基本操作方法组合在一起形成一个总算法或一个总行为的方法。这个模板方法定义在抽象类中,并由子类不加以修改地完全继承下来。模板方法是一个具体方法,它给出了一个顶层逻辑框架,而逻辑的组成步骤在抽象类中可以是具体方法,也可以是抽象方法。
基本方法是实现算法各个步骤的方法,是模板方法的组成部分。基本方法又可以分为三种:抽象方法(Abstract Method)、具体方法(Concrete Method)和钩子方法(Hook Method)。
-
抽象方法:一个抽象方法由抽象类声明、由其具体子类实现。
-
具体方法:一个具体方法由一个抽象类或具体类声明并实现,其子类可以进行覆盖也可以直接继承。
-
钩子方法:可以与一些具体步骤 "挂钩" ,以实现在不同条件下执行模板方法中的不同步骤
以制造手机的固定步骤为例
package main import "fmt" // 抽象类,手机制造流水线,包裹一个模板的全部实现步骤 type Phone interface { AssembleBasicFrame() //组装基架 AssembleBattery() //组装电池 AssembleCamera() //组装摄像头 AssembleScreen() //组装屏幕 AddThings() // 选配 WantAddThings() bool //是否选配 Hook函数 } // 封装一套流程模板,让具体的制作流程继承且实现 type template struct { p Phone } // 封装的固定模板 func (t *template) MakePhone() { if t == nil { return } t.p.AssembleBasicFrame() t.p.AssembleBattery() t.p.AssembleCamera() t.p.AssembleScreen() //子类可以重写该方法来决定是否执行下面动作 if t.p.WantAddThings() == true { t.p.AddThings() } } // 具体的模板子类 制作咖啡 type MakeHuawei struct { template //继承模板 } func NewMakeHuawei() *MakeHuawei { makeHuawei := new(MakeHuawei) //p 为Phone,是MakeHuawei的接口,这里需要给接口赋值,指向具体的子类对象 //来触发p全部接口方法的多态特性。 makeHuawei.p = makeHuawei return makeHuawei } func (mh *MakeHuawei) AssembleBasicFrame() { fmt.Println("组装基架") } func (mh *MakeHuawei) AssembleBattery() { fmt.Println("组装电池") } func (mh *MakeHuawei) AssembleCamera() { fmt.Println("组装摄像头") } func (mh *MakeHuawei) AssembleScreen() { fmt.Println("组装屏幕") } func (mh *MakeHuawei) AddThings() { fmt.Println("选配") } func (mh *MakeHuawei) WantAddThings() bool { return true // 启动钩子 } func main() { makeHuawei := NewMakeHuawei() makeHuawei.MakePhone() }
优点:
-
在父类中形式化地定义一个算法,而由它的子类来实现细节的处理,在子类实现详细的处理算法时并不会改变算法中步骤的执行次序。
-
模板方法模式是一种代码复用技术,它在类库设计中尤为重要,它提取了类库中的公共行为,将公共行为放在父类中,而通过其子类来实现不同的行为,它鼓励我们恰当使用继承来实现代码复用。
-
可实现一种反向控制结构,通过子类覆盖父类的钩子方法来决定某一特定步骤是否需要执行。
-
在模板方法模式中可以通过子类来覆盖父类的基本方法,不同的子类可以提供基本方法的不同实现,更换和增加新的子类很方便,符合单一职责原则和开闭原则。
缺点:
- 需要为每一个基本方法的不同实现提供一个子类,如果父类中可变的基本方法太多,将会导致类的个数增加,系统更加庞大,设计也更加抽象。
适用场景:
-
具有统一的操作步骤或操作过程
-
具有不同的操作细节
-
存在多个具有同样操作步骤的应用场景,但某些具体的操作细节却各不相同
任务执行中心
策略模式
策略设计模式是一种行为设计模式。当在处理一个业务时,有多种处理方式,并且需要在运行时决定使哪一种具体实现时,就会使用策略模式。
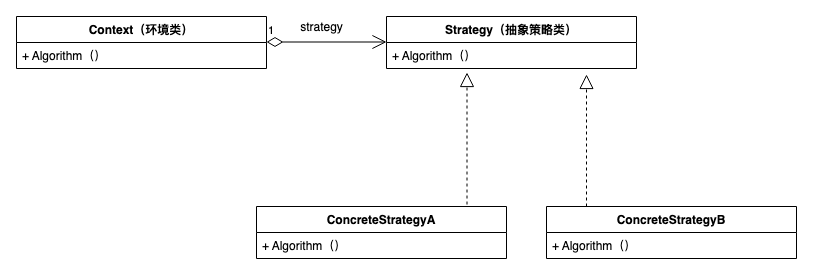
- Context(环境类):环境类是使用算法的角色,它在解决某个问题(即实现某个方法)时可以采用多种策略。在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略。
- Strategy(抽象策略类):它为所支持的算法声明了抽象方法,是所有策略类的父类,它可以是抽象类或具体类,也可以是接口。环境类通过抽象策略类中声明的方法在运行时调用具体策略类中实现的算法。
- ConcreteStrategy(具体策略类):它实现了在抽象策略类中声明的算法,在运行时,具体策略类将覆盖在环境类中定义的抽象策略类对象,使用一种具体的算法实现某个业务处理。
以使用不同的手机为不同的策略
package main import "fmt" // 手机策略(抽象的策略) type PhoneStrategy interface { UsePhone() //使用手机 } // 具体的策略 type IPhone struct{} func (i *IPhone) UsePhone() { fmt.Println("使用iphone 打电话") } // 具体的策略 type Huawei struct{} func (h *Huawei) UsePhone() { fmt.Println("使用华为 打电话") } // 环境类 type Person struct { phone PhoneStrategy //拥有一个抽象的策略 } // 设置一个策略 func (per *Person) SetPhoneStrategy(p PhoneStrategy) { per.phone = p } func (per *Person) Call() { per.phone.UsePhone() //调用策略 } func main() { person := Person{} person.SetPhoneStrategy(new(Huawei)) person.Call() }
优点:
-
策略模式提供了对“开闭原则”的完美支持,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
-
使用策略模式可以避免多重条件选择语句。多重条件选择语句不易维护,它把采取哪一种算法或行为的逻辑与算法或行为本身的实现逻辑混合在一起,将它们全部硬编码(Hard Coding)在一个庞大的多重条件选择语句中,比直接继承环境类的办法还要原始和落后。
-
策略模式提供了一种算法的复用机制。由于将算法单独提取出来封装在策略类中,因此不同的环境类可以方便地复用这些策略类。
缺点:
-
客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这就意味着客户端必须理解这些算法的区别,以便适时选择恰当的算法。换言之,策略模式只适用于客户端知道所有的算法或行为的情况。
-
策略模式将造成系统产生很多具体策略类,任何细小的变化都将导致系统要增加一个新的具体策略类。 适用场景:
-
如果在一个系统里面有许多类,它们仅仅在行为上有区别,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为;
-
一个系统需要动态地在几种算法中选择一种;
-
如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。 调度中心策略、触达中心
模板方法和策略模式的区别?
策略模式定义了一个算法家族,并让这些算法可以互相转换。正因为每一个算法都被封装起来了,所以客户可以轻易地使用不同的算法。
虽然两者都封装了算法,但是意图是不一样的:模板方法的工作是定义一个算法大纲,而由子类定义其中某些步骤的内容,它可以改变个别步骤的实现细节但是算法的结构依然维持不变。不过策略模式是使用组合委托的方法,通过对象组合可以让客户选择算法的实现。
也就是说模板方法对算法的控制权更多,而且不会重复代码,一般情况下效率高一些,而策略模式更加灵活,更具有弹性。
命令模式
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。

- Command(抽象命令类):抽象命令类一般是一个抽象类或接口,在其中声明了用于执行请求的execute()等方法,通过这些方法可以调用请求接收者的相关操作。
- ConcreteCommand(具体命令类):具体命令类是抽象命令类的子类,实现了在抽象命令类中声明的方法,它对应具体的接收者对象,将接收者对象的动作绑定其中。在实现execute()方法时,将调用接收者对象的相关操作(Action)。
- Invoker(调用者):调用者即请求发送者,它通过命令对象来执行请求。一个调用者并不需要在设计时确定其接收者,因此它只与抽象命令类之间存在关联关系。在程序运行时可以将一个具体命令对象注入其中,再调用具体命令对象的execute()方法,从而实现间接调用请求接收者的相关操作。
- Receiver(接收者):接收者执行与请求相关的操作,它具体实现对请求的业务处理。
package main import "fmt" // 手机-命令接收者 type IPhone struct{} func (d *IPhone) sendEmail() { fmt.Println("发邮件") } func (d *IPhone) call() { fmt.Println("打电话") } // 抽象的命令 type Command interface { Execute() } // 发邮件的命令 type CommandSendEmail struct { phone *IPhone } func (cmd *CommandSendEmail) Execute() { cmd.phone.sendEmail() } // 打电话的命令 type CommandCall struct { phone *IPhone } func (cmd *CommandCall) Execute() { cmd.phone.call() } // siri-调用命令者 type Siri struct { CmdList []Command //收集的命令集合 } // 发送命令的方法 func (s *Siri) Notify() { if s.CmdList == nil { return } for _, cmd := range s.CmdList { cmd.Execute() //执行命令 } } // 发送命令 func main() { phone := new(IPhone) cmdSendEmail := CommandSendEmail{phone} cmdCall := CommandCall{phone} siri := new(Siri) siri.CmdList = append(siri.CmdList, &cmdSendEmail, &cmdCall) siri.Notify() }
优点:
-
降低系统的耦合度。由于请求者与接收者之间不存在直接引用,因此请求者与接收者之间实现完全解耦,相同的请求者可以对应不同的接收者,同样,相同的接收者也可以供不同的请求者使用,两者之间具有良好的独立性。
-
新的命令可以很容易地加入到系统中。由于增加新的具体命令类不会影响到其他类,因此增加新的具体命令类很容易,无须修改原有系统源代码,甚至客户类代码,满足“开闭原则”的要求。
-
可以比较容易地设计一个命令队列或宏命令(组合命令)。
缺点:
- 使用命令模式可能会导致某些系统有过多的具体命令类。因为针对每一个对请求接收者的调用操作都需要设计一个具体命令类,因此在某些系统中可能需要提供大量的具体命令类,这将影响命令模式的使用。
适用场景:
-
系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。请求调用者无须知道接收者的存在,也无须知道接收者是谁,接收者也无须关心何时被调用。
-
系统需要在不同的时间指定请求、将请求排队和执行请求。一个命令对象和请求的初始调用者可以有不同的生命期,换言之,最初的请求发出者可能已经不在了,而命令对象本身仍然是活动的,可以通过该命令对象去调用请求接收者,而无须关心请求调用者的存在性,可以通过请求日志文件等机制来具体实现。
-
系统需要将一组操作组合在一起形成宏命令。
观察者模式

- Subject(被观察者或目标,抽象主题):被观察的对象。当需要被观察的状态发生变化时,需要通知队列中所有观察者对象。Subject需要维持(添加,删除,通知)一个观察者对象的队列列表。
- ConcreteSubject(具体被观察者或目标,具体主题):被观察者的具体实现。包含一些基本的属性状态及其他操作。
- Observer(观察者):接口或抽象类。当Subject的状态发生变化时,Observer对象将通过一个callback函数得到通知。
- ConcreteObserver(具体观察者):观察者的具体实现。得到通知后将完成一些具体的业务逻辑处理。 以手机发布会为例,苹果新品发布会,会导致iphone15涨价,iphone14降价20%,iphone13降价30%
package main import "fmt" //--------- 抽象层 -------- // 抽象的观察者 type Listener interface { OnIphone15Coming() //观察者得到通知后要触发的动作 } // 抽象的消息通知者 type Notifier interface { AddListener(listener Listener) RemoveListener(listener Listener) Notify() } // --------- 实现层 -------- // 观察者 其他系列手机 type Iphone13 struct { price float64 } func (i *Iphone13) OnIphone15Coming() { fmt.Println("iphone 13 降价 30%", i.price*0.7) } type Iphone14 struct { price float64 } func (i *Iphone14) OnIphone15Coming() { fmt.Println("iphone 14 降价 20%", i.price*0.8) } // 通知者:媒体 type Media struct { listenerList []Listener //需要通知的全部观察者集合 } func (w *Media) AddListener(listener Listener) { w.listenerList = append(w.listenerList, listener) } func (w *Media) RemoveListener(listener Listener) { for index, l := range w.listenerList { //找到要删除的元素位置 if listener == l { //将删除的点前后的元素链接起来 w.listenerList = append(w.listenerList[:index], w.listenerList[index+1:]...) break } } } func (w *Media) Notify() { for _, listener := range w.listenerList { //依次调用全部观察的具体动作 listener.OnIphone15Coming() } } func main() { weibo := new(Media) weibo.AddListener(&Iphone14{price: 10000}) weibo.AddListener(&Iphone13{price: 8000}) fmt.Println("iphone 15要来了,iphone开始在微博官宣") weibo.Notify() }
优点:
-
观察者模式可以实现表示层和数据逻辑层的分离,定义了稳定的消息更新传递机制,并抽象了更新接口,使得可以有各种各样不同的表示层充当具体观察者角色。
-
观察者模式在观察目标和观察者之间建立一个抽象的耦合。观察目标只需要维持一个抽象观察者的集合,无须了解其具体观察者。由于观察目标和观察者没有紧密地耦合在一起,因此它们可以属于不同的抽象化层次。
-
观察者模式支持广播通信,观察目标会向所有已注册的观察者对象发送通知,简化了一对多系统设计的难度。
-
观察者模式满足“开闭原则”的要求,增加新的具体观察者无须修改原有系统代码,在具体观察者与观察目标之间不存在关联关系的情况下,增加新的观察目标也很方便。
缺点:
-
如果一个观察目标对象有很多直接和间接观察者,将所有的观察者都通知到会花费很多时间。
-
如果在观察者和观察目标之间存在循环依赖,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。
-
观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
适用场景:
-
一个抽象模型有两个方面,其中一个方面依赖于另一个方面,将这两个方面封装在独立的对象中使它们可以各自独立地改变和复用。
-
一个对象的改变将导致一个或多个其他对象也发生改变,而并不知道具体有多少对象将发生改变,也不知道这些对象是谁。
-
需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
本文作者:唐文杰
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!